INFO 557: Neural Networks – Course Visualizations
Supplemental visualizations for Greg Chism, Assistant Professor of Practice at the University of Arizona, College of Information Science. Course: INFO 557: Neural Networks — covering neural network architectures, deep learning theory, and optimization.
Probabilistic Foundations
-

Softmax Temperature Explorer — interactive explainer (T. Pavlic)
Adjust the temperature of the softmax (Gibbs) distribution and watch how it interpolates between uniform exploration and greedy exploitation — the same mechanism underlying SA acceptance and MaxEnt methods.
-

Maximum Entropy (MaxEnt) — interactive explainer (T. Pavlic)
Explore how the Maximum Entropy principle selects the least-assumptive distribution consistent with known constraints — and how this derivation produces the Gibbs/softmax distribution that underlies SA acceptance probabilities.
-

Boltzmann Distribution via Random Exchange — interactive explainer (T. Pavlic)
N agents repeatedly trade random amounts of a conserved quantity — watch any starting distribution relax to the maximum-entropy Boltzmann (exponential) equilibrium, confirming the statistical mechanics origin of the Gibbs distribution.
Neural Networks
-

The AI Landscape — An Interactive Map
Explore how artificial intelligence, machine learning, and neural networks relate — see where INFO 557 fits within the broader AI landscape.
-
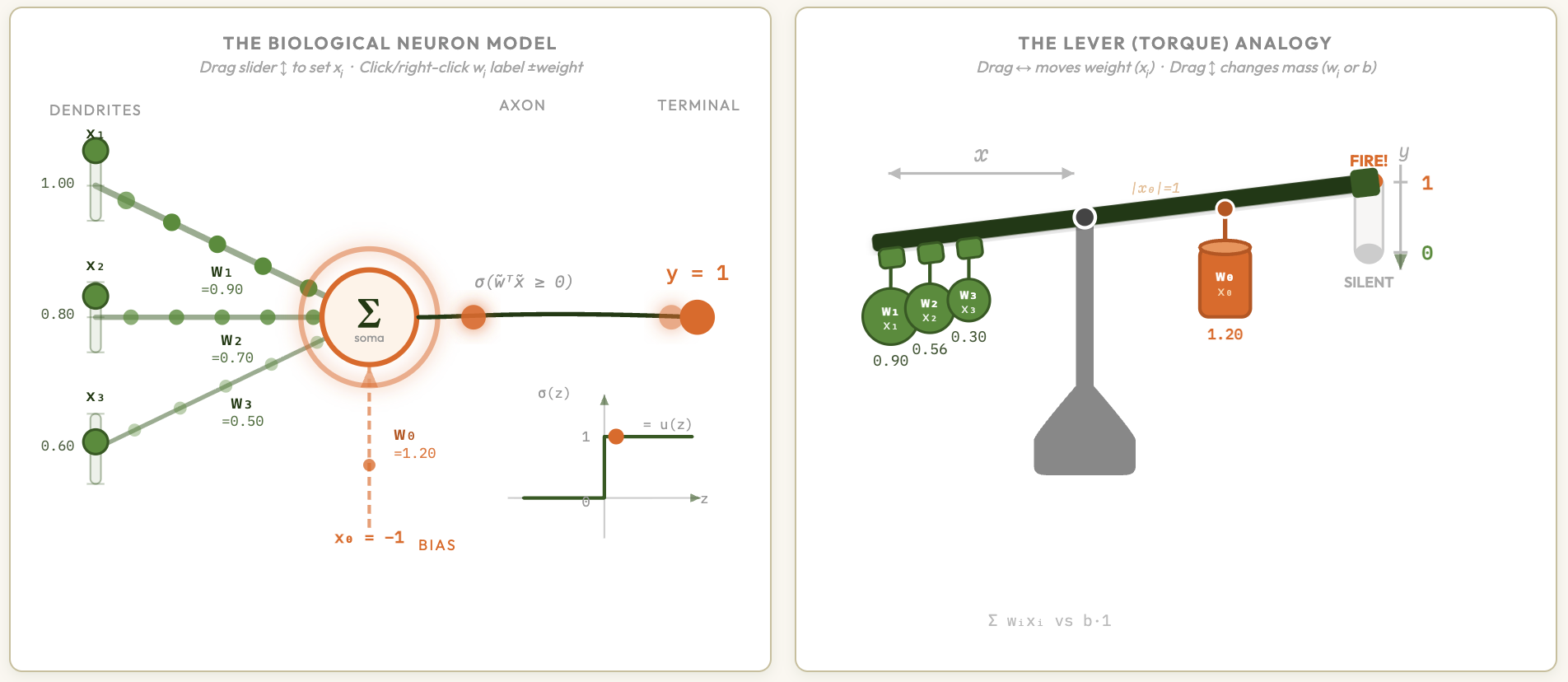
Single-Layer Perceptron — Neuron & Lever Explainer (T. Pavlic)
Animated connection between the biological neuron and the linear classifier — adjust synaptic weights and inputs to watch the decision boundary shift in real time.
-
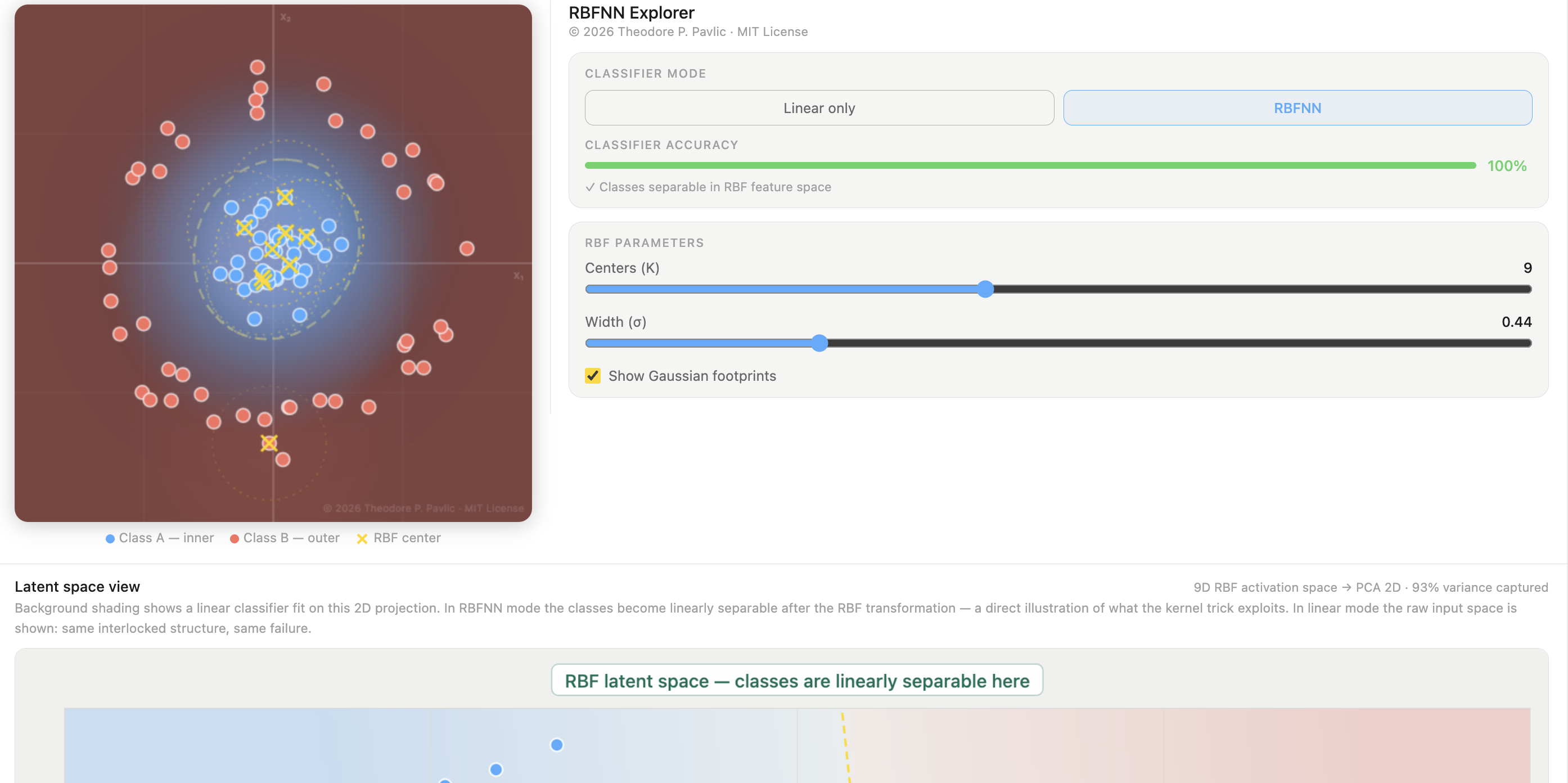
Radial Basis Function Neural Network — interactive explorer
Adjust centers, widths, and weights of radial kernels to see how an RBF network builds up an approximation — making the hidden-layer geometry of this bio-inspired architecture tangible.
-
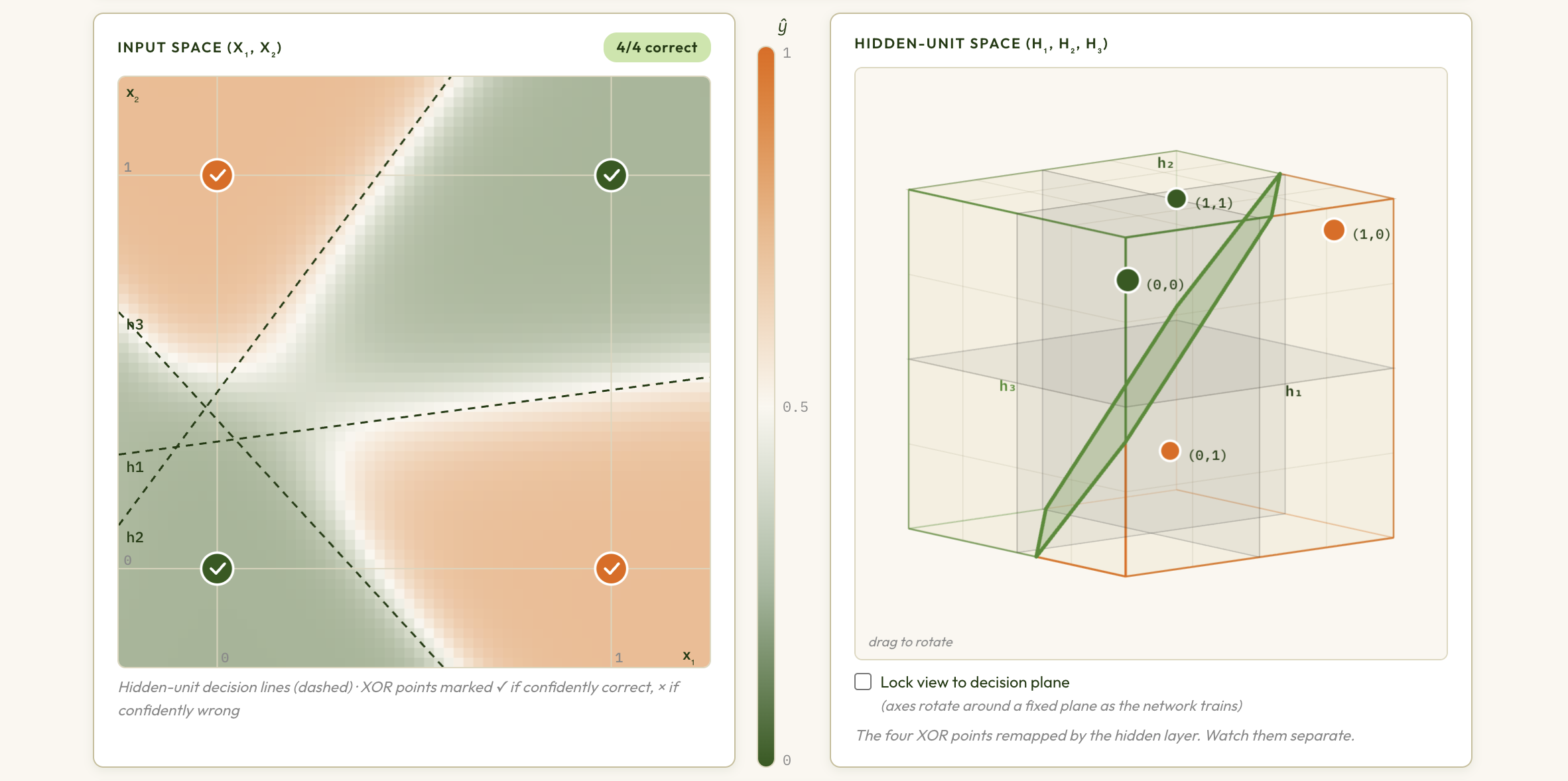
Multi-Layer Perceptron & Backpropagation — interactive explorer (T. Pavlic)
Explore how hidden layers let a network solve XOR and other non-linearly separable tasks, and trace backpropagation as gradient flow through the network's architecture.
-
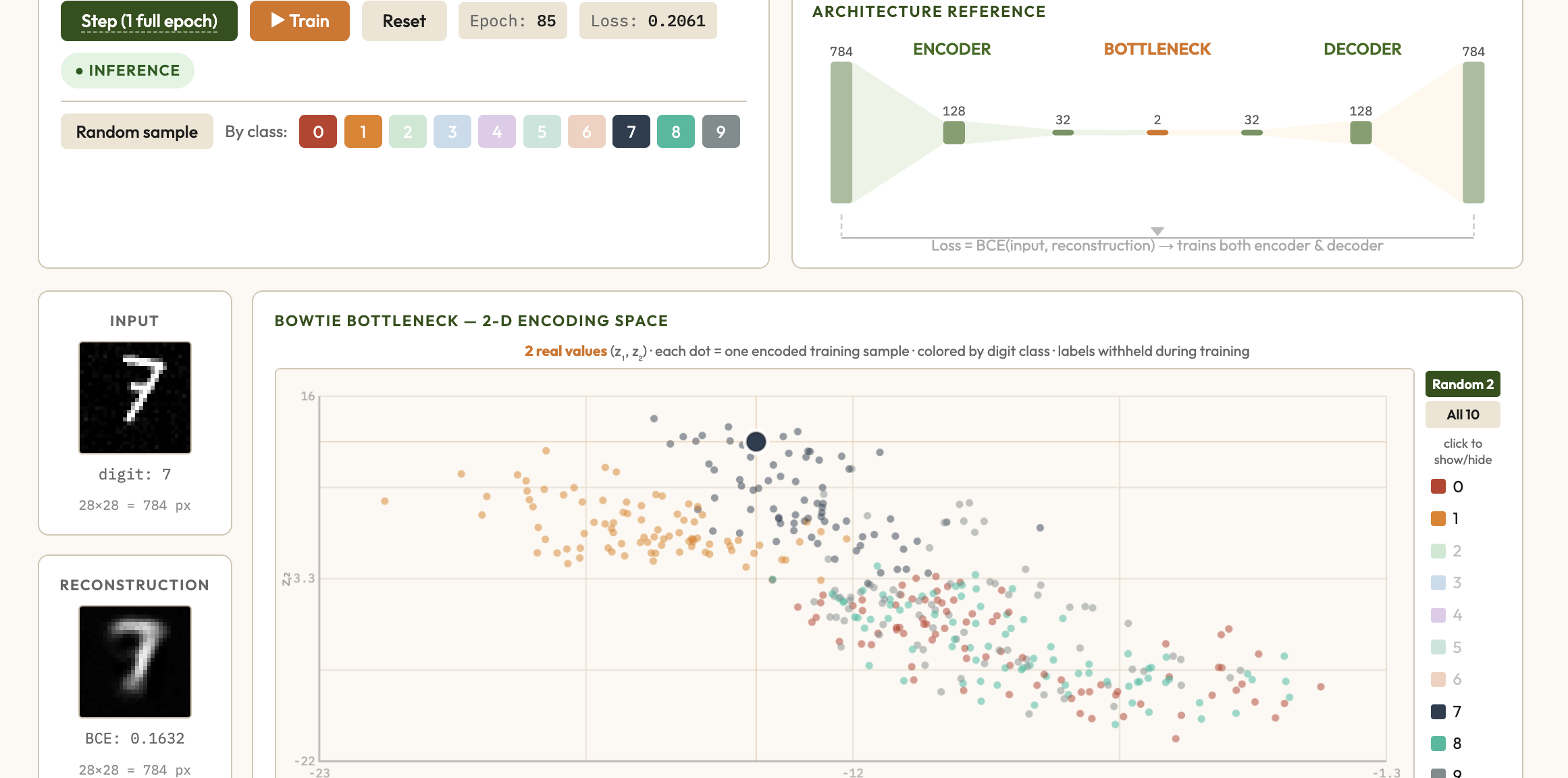
Autoencoder Explorer — interactive explainer
Train a deep autoencoder on MNIST-like digit data and watch the 2-D bottleneck encoding cluster by class — a hands-on demonstration of unsupervised representation learning with neural networks.
-
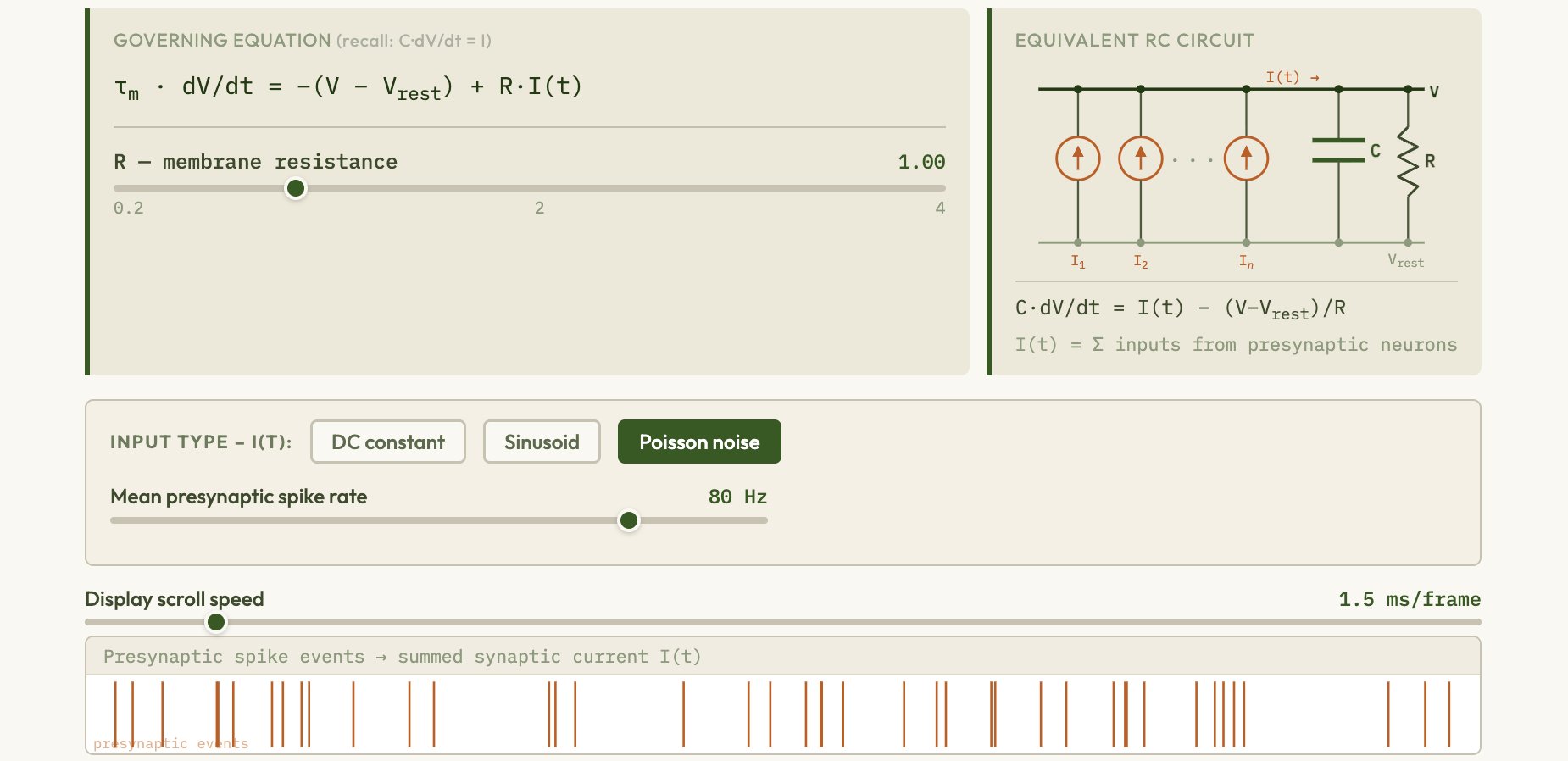
Spiking Neural Networks — interactive explorer
Simulate leaky integrate-and-fire neurons, visualize spike trains and membrane potentials, and explore Spike-Timing-Dependent Plasticity (STDP) — the biologically plausible Hebbian learning rule linking neural firing timing to synaptic weight changes.
-
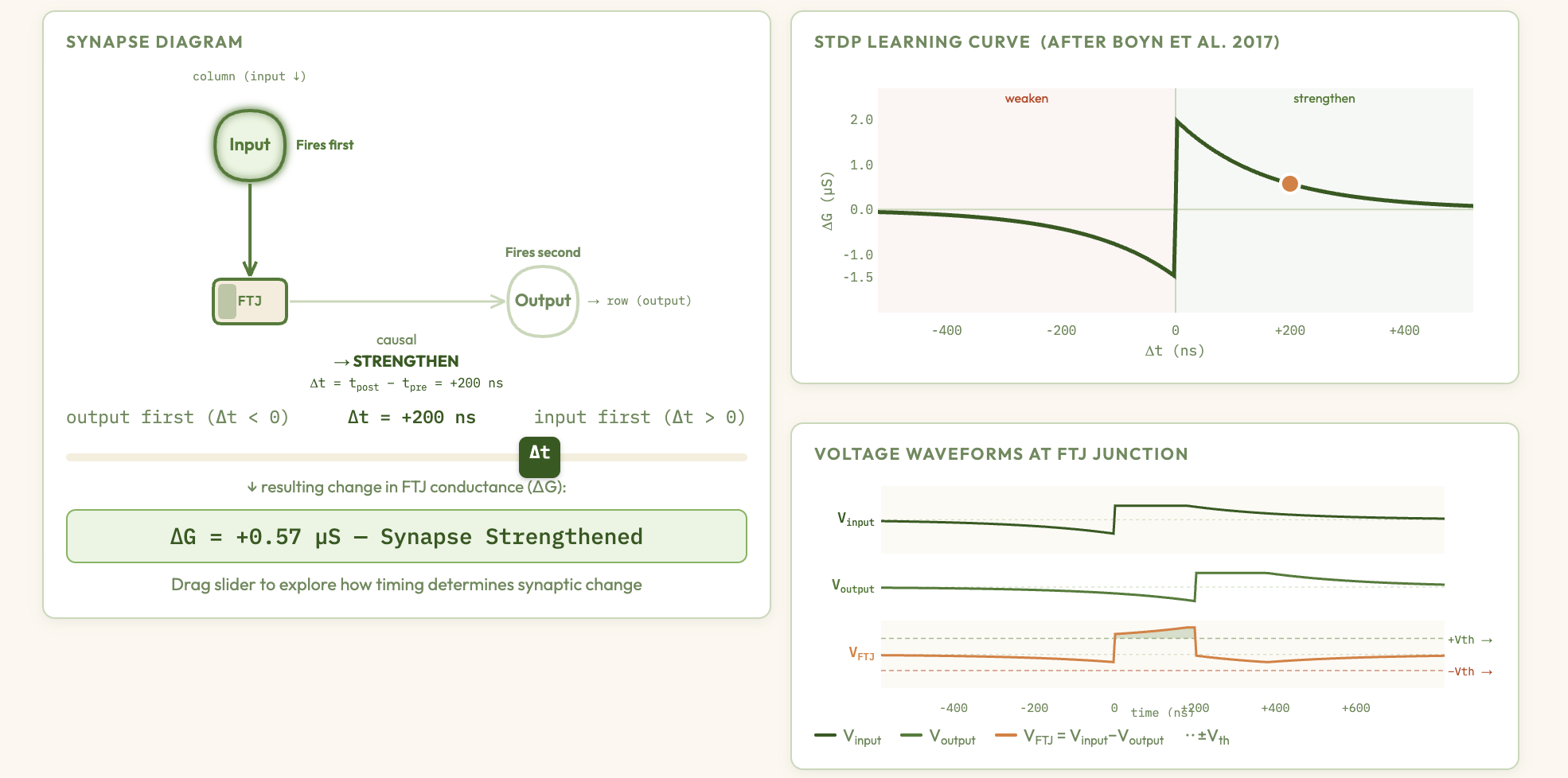
Ferroelectric Memristor Synapses & Crossbar Learning — interactive explainer
Explore how ferroelectric memristor synapses in a crossbar array implement Spike-Timing-Dependent Plasticity (STDP) — adjust pulse timings, device parameters, and network architecture to watch Hebbian learning emerge from nanoscale physics.
-
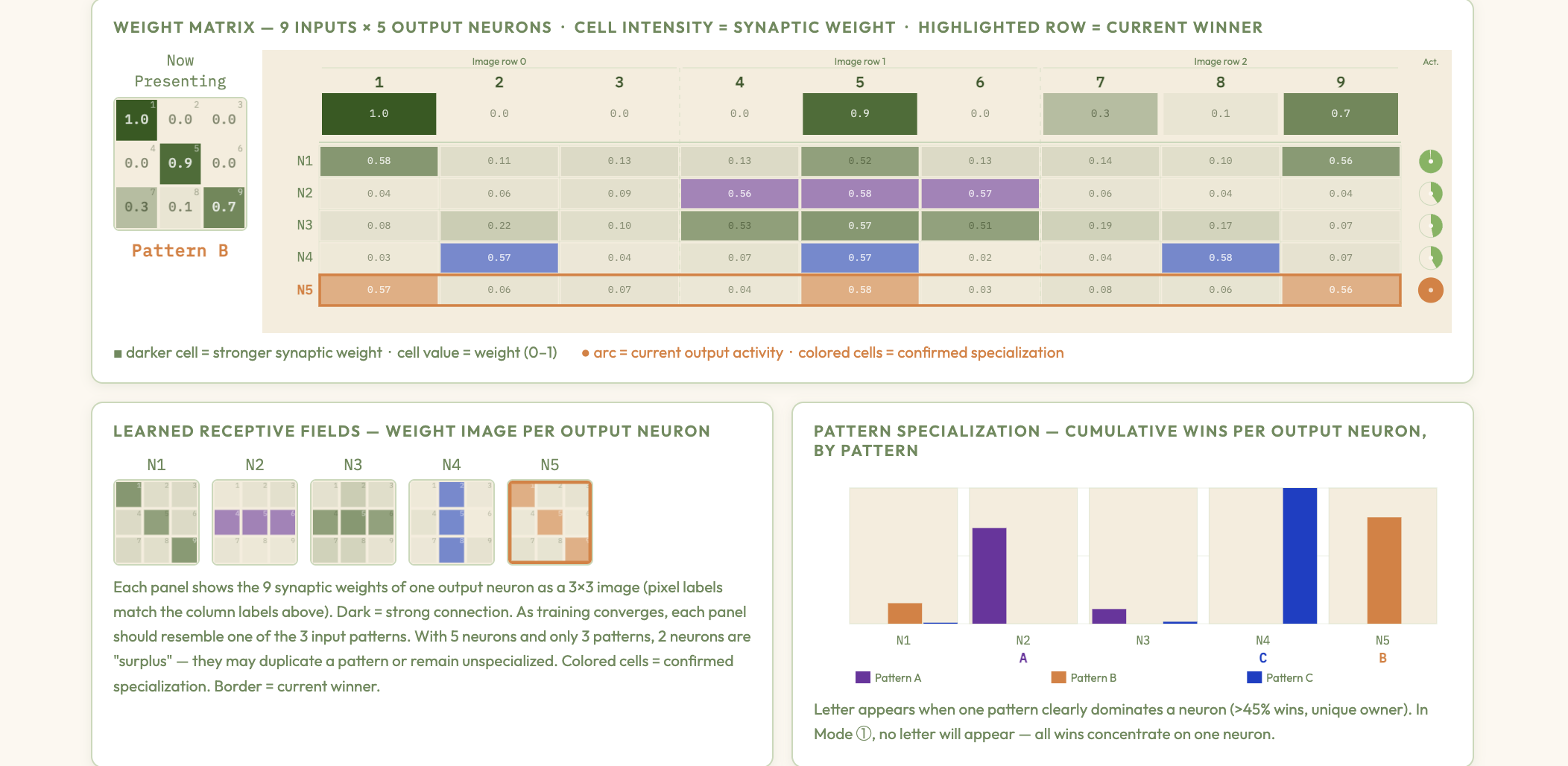
Hebbian Learning & Competitive Clustering — interactive explainer
Explore how Hebbian synaptic update rules combined with lateral inhibition drive winner-take-all competition, organizing input patterns into distinct clusters without supervision — bridging the STDP memristor demo to classical unsupervised ANN learning.
-

Recurrent Networks & Temporal Supervision Explorer — interactive explainer
Trace the evolution from Time-Delay Neural Networks to RNNs with output feedback and autoregressive latent-state RNNs, train them via Backpropagation Through Time (BPTT), and follow a visual guide to gated architectures (LSTM, GRU) that solve the vanishing-gradient problem.
-
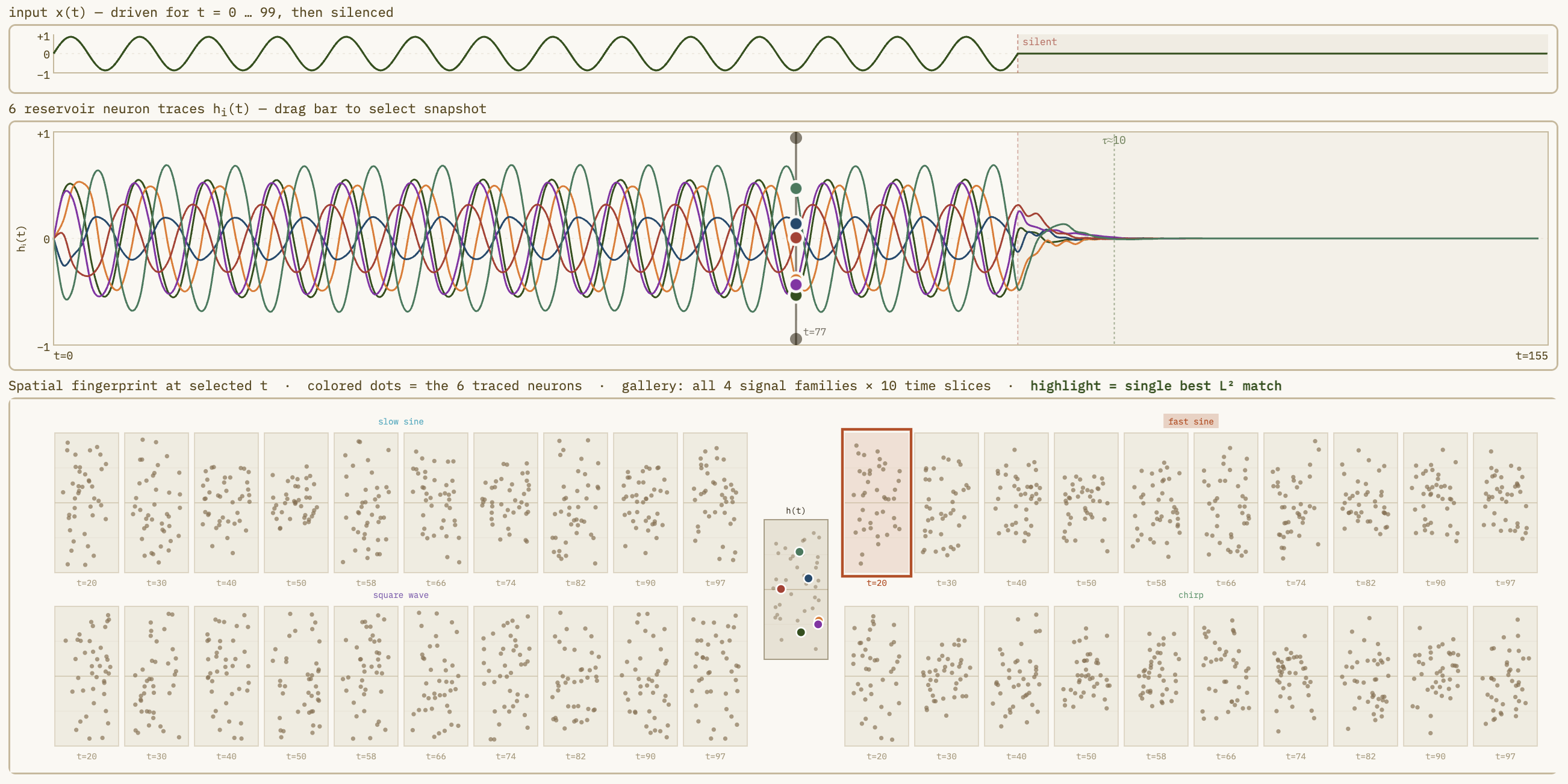
Reservoir Computing — Echo State Network Explorer
Adjust spectral radius, sparsity, and input scaling to watch a fixed random reservoir project inputs into a high-dimensional state space where a simple linear readout can separate complex dynamics — the key insight of reservoir computing via Echo State Networks.
-

Transformer Architecture Explorer — interactive explainer
Step through scaled dot-product self-attention, multi-head attention, positional encodings, and Vision Transformers (ViT) with live attention-map and patch-embedding visualizations.
-
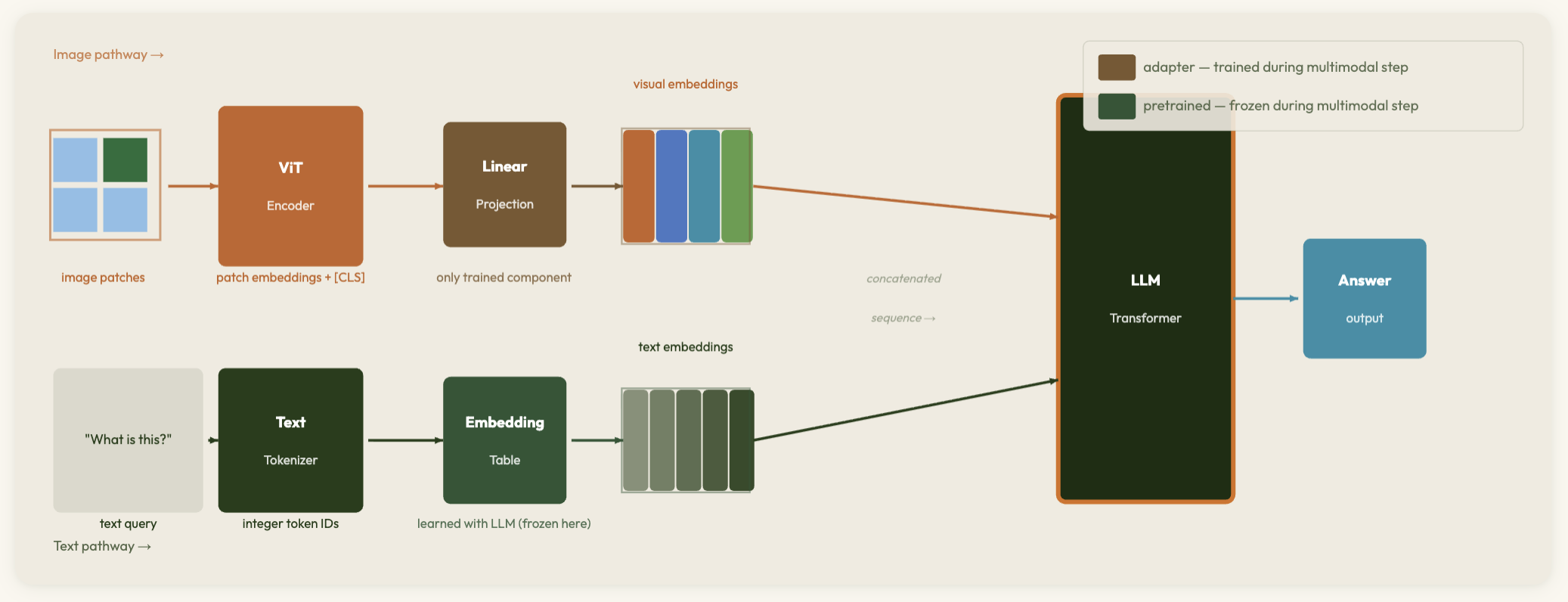
Toward Multimodal AI — interactive explainer
Trace the path from CNNs and patch embeddings to Vision Transformers, CLIP-style contrastive pretraining, and modern multimodal architectures — showing how a single attention mechanism unifies vision and language.
-

Activation Functions — Interactive Explorer
Adjust parameters for ReLU, Leaky ReLU, ELU, Swish, Sigmoid, Tanh, Maxout, and Linear units — see the function and derivative plots side by side with annotations on saturation, vanishing gradients, and when to use each.
-

Loss Functions — Interactive Explorer
See how MSE, MAE, Cross-Entropy, Hinge, and Huber loss respond to predictions — understand why choosing the right loss function matters for regression vs classification.
-

Gradient Descent & Cost Functions — Interactive Explorer
Animate gradient descent on 2D loss landscapes for MSE, MAE, Cross-Entropy, and Hinge Loss — tune learning rate, compare Batch GD, SGD, and Mini-Batch, and discover saddle points, flat regions, and vanishing gradients live.
-

Backpropagation & Computational Graphs — interactive explorer
Step through forward and backward passes on a live computational graph — watch values propagate forward and gradients flow back via the chain rule with real numbers, across three network examples: single neuron, XOR network, and 3-layer deep network.
-

L1 & L2 Regularization — interactive explorer
Visualize how L1 and L2 penalties shape weight distributions, decision boundaries, and optimization paths — and why L1 produces sparsity while L2 does not.
-

Dropout Regularization — interactive explorer
Watch nodes randomly drop during training, then see the full network activate at inference with inverted-dropout weight scaling — exploring how dropout prevents overfitting by training an ensemble of subnetworks.
-

Early Stopping — interactive explorer
Watch training and validation loss diverge as a neural network overfits — step through epochs to find the optimal stopping point, and see how patience and model complexity affect when to halt training.
-

Optimization Algorithms — interactive explorer
Watch SGD, Momentum, AdaGrad, RMSProp, and Adam navigate the Rosenbrock banana landscape simultaneously — see why adaptive methods converge faster and how momentum smooths oscillation.
-

Learning Rate Schedules — Interactive Explorer
Compare constant, step decay, cosine annealing, warmup, and cyclical learning rate strategies — see how schedule choice shapes loss curves and convergence speed.
-

Batch Normalization — Interactive Explorer
Watch activation distributions shift and stabilize across layers — see how batch norm prevents internal covariate shift and accelerates training.
-

Convolutional Filters — Interactive Explorer
Watch filters slide across inputs to produce feature maps — explore how stride, padding, pooling, and CNN architecture transform spatial data.
-

Graph Neural Networks — Interactive Explorer
Watch message passing propagate through graphs — see how GNNs learn node, edge, and graph-level representations for molecules, social networks, and citation graphs.
-

Vanishing & Exploding Gradients — Interactive Explorer
Watch gradient magnitudes shrink or explode as they propagate backward through deep networks — and see how batch norm, skip connections, and careful initialization keep training stable.
-

LIME — Local Interpretable Model-Agnostic Explanations
Click any point in the decision space to generate a local linear explanation — see how LIME approximates complex model decisions with simple interpretable models.
-

Gradient Attribution — Interactive Explorer
See which input features drive model predictions — explore saliency maps, integrated gradients, and SmoothGrad side by side.
-

Knowledge Distillation — Interactive Explorer
Watch a small student network learn from a large teacher's soft predictions — see how temperature scaling and soft labels transfer richer knowledge than hard labels alone.