# Data Manipulation and Analysis
import pandas as pd
import numpy as np
# Data Visualization
import seaborn as sns
import matplotlib.pyplot as plt
# Machine Learning
from sklearn.decomposition import PCA
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Statistical Analysis
import statsmodels.api as sm
import scipy.stats as stats
# Increase font size of all Seaborn plot elements
sns.set(font_scale=1.25)
# Set Seaborn theme
sns.set_theme(style="whitegrid", palette="colorblind")PCA + Clustering
INFO Data Visualization and Analysis - Week 5
Datasets
Human Freedom Index
The Human Freedom Index is a report that attempts to summarize the idea of “freedom” through variables for many countries around the globe.
Mean imputation
How it Works: Replace missing values with the arithmetic mean of the non-missing values in the same variable.
Pros:
- Easy and fast.
- Works well with small numerical datasets
Cons:
- It only works on the column level.
- Will give poor results on encoded categorical features.
- Not very accurate.
- Doesn’t account for the uncertainty in the imputations.
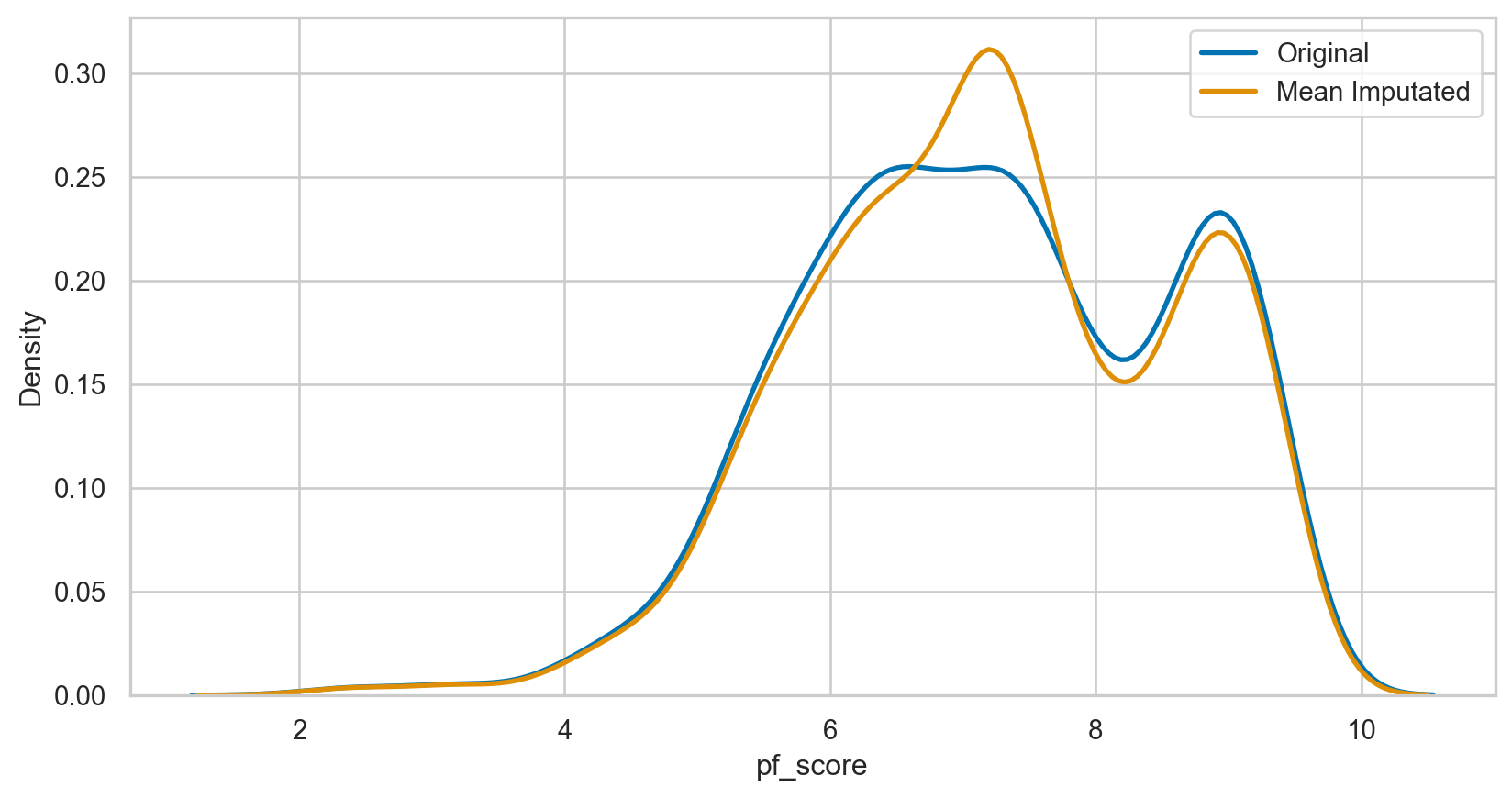
hfi_copy = hfi
mean_imputer = SimpleImputer(strategy = 'mean')
hfi_copy['mean_pf_score'] = mean_imputer.fit_transform(hfi_copy[['pf_score']])
mean_plot = sns.kdeplot(data = hfi_copy, x = 'pf_score', linewidth = 2, label = "Original")
mean_plot = sns.kdeplot(data = hfi_copy, x = 'mean_pf_score', linewidth = 2, label = "Mean Imputated")
plt.legend()
plt.show()Median imputation
How it Works: Replace missing values with the median of the non-missing values in the same variable.
Pros (same as mean):
- Easy and fast.
- Works well with small numerical datasets
Cons (same as mean):
- It only works on the column level.
- Will give poor results on encoded categorical features.
- Not very accurate.
- Doesn’t account for the uncertainty in the imputations.
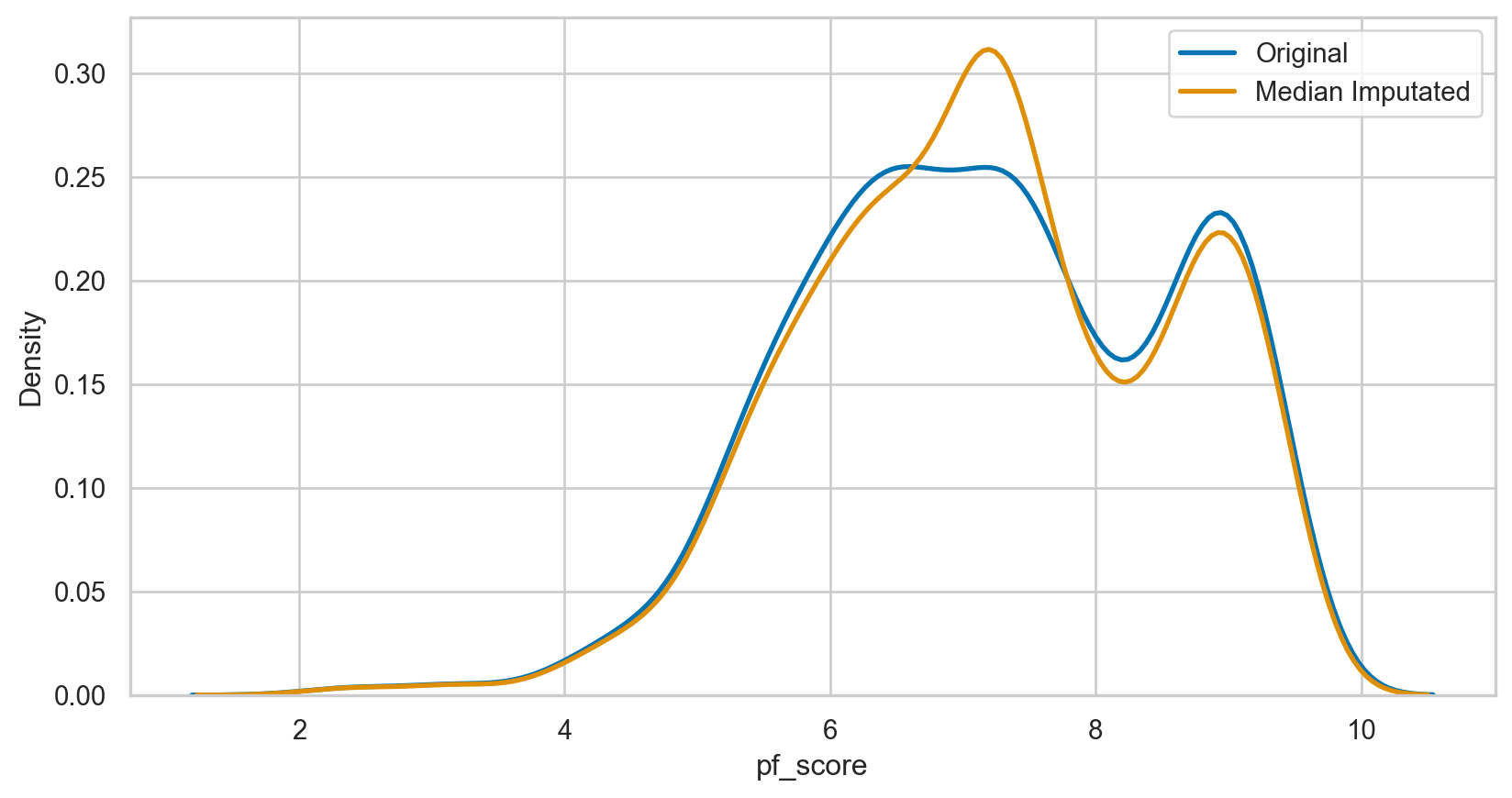
median_imputer = SimpleImputer(strategy = 'median')
hfi_copy['median_pf_score'] = median_imputer.fit_transform(hfi_copy[['pf_score']])
median_plot = sns.kdeplot(data = hfi_copy, x = 'pf_score', linewidth = 2, label = "Original")
median_plot = sns.kdeplot(data = hfi_copy, x = 'median_pf_score', linewidth = 2, label = "Median Imputated")
plt.legend()
plt.show()Dimensional reduction: applied
numeric_cols = hfi.select_dtypes(include = [np.number]).columns
# Applying mean imputation only to numeric columns
hfi[numeric_cols] = hfi[numeric_cols].fillna(hfi[numeric_cols].mean())
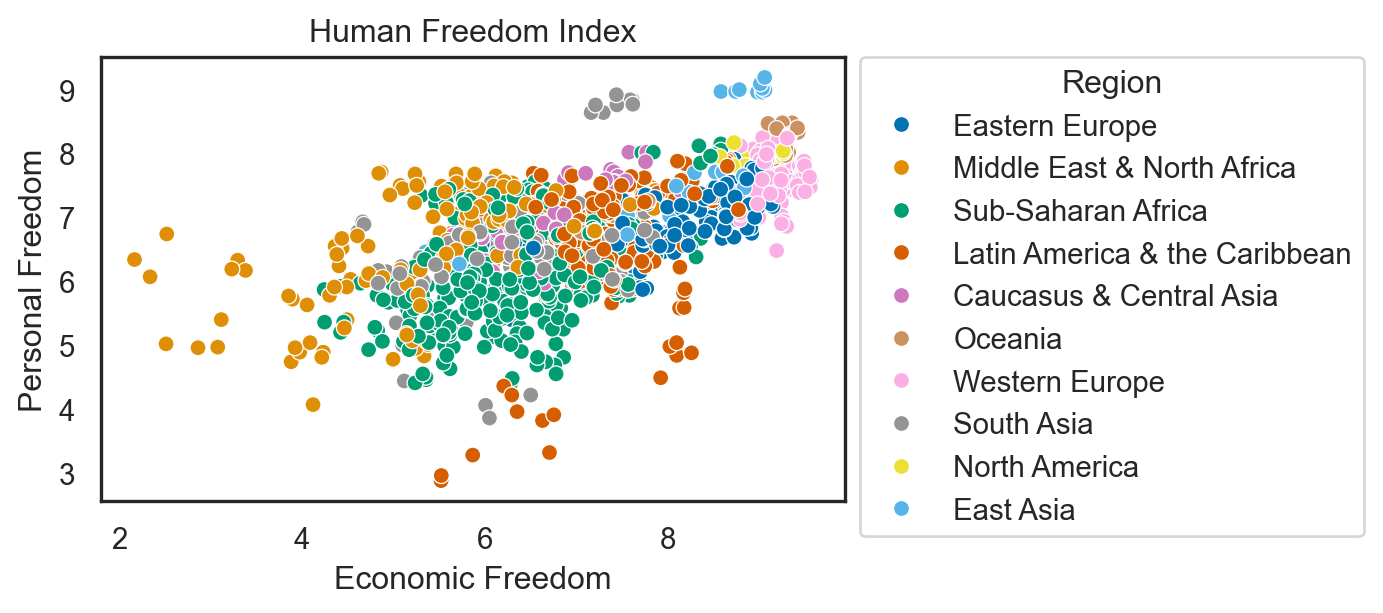
features = ['pf_rol_procedural', 'pf_rol_civil', 'pf_rol_criminal', 'pf_rol', 'hf_score', 'hf_rank', 'hf_quartile']
x = hfi.loc[:, features].values
y = hfi.loc[:, 'region'].values
x = StandardScaler().fit_transform(x)Code
pca = PCA(n_components = 2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents, columns = ['principal component 1', 'principal component 2'])
pca_variance_explained = pca.explained_variance_ratio_
print("Variance explained:", pca_variance_explained, "\n", principalDf)Variance explained: [0.76138995 0.15849799]
principal component 1 principal component 2
0 5.164625e-01 -9.665680e-01
1 -2.366765e+00 1.957381e+00
2 -2.147729e+00 1.664483e+00
3 -2.784437e-01 8.066415e-01
4 3.716205e-01 -4.294282e-01
... ... ...
1453 -4.181375e+00 -4.496988e-01
1454 -5.213024e-01 6.010449e-01
1455 1.374342e-16 -2.907121e-16
1456 -1.545577e+00 -5.422255e-01
1457 -3.669011e+00 4.294948e-01
[1458 rows x 2 columns]Code
# Combining the scatterplot of principal components with the scree plot using the correct column names
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (12, 5))
# Scatterplot of Principal Components
axes[0].scatter(principalDf['principal component 1'], principalDf['principal component 2'])
for i in range(len(pca.components_)):
axes[0].arrow(0, 0, pca.components_[i, 0], pca.components_[i, 1], head_width = 0.1, head_length = 0.15, fc = 'r', ec = 'r', linewidth = 2)
axes[0].text(pca.components_[i, 0] * 1.2, pca.components_[i, 1] * 1.2, f'Eigenvector {i+1}', color = 'r', fontsize = 12)
axes[0].set_xlabel('Principal Component 1')
axes[0].set_ylabel('Principal Component 2')
axes[0].set_title('Scatterplot of Principal Components with Eigenvectors')
axes[0].grid()
# Scree Plot for PCA
axes[1].bar(range(1, len(pca_variance_explained) + 1), pca_variance_explained, alpha = 0.6, color = 'g', label = 'Individual Explained Variance')
axes[1].set_ylabel('Explained variance ratio')
axes[1].set_xlabel('Principal components')
axes[1].set_title('Scree Plot for PCA')
axes[1].legend(loc='best')
plt.tight_layout()
plt.show()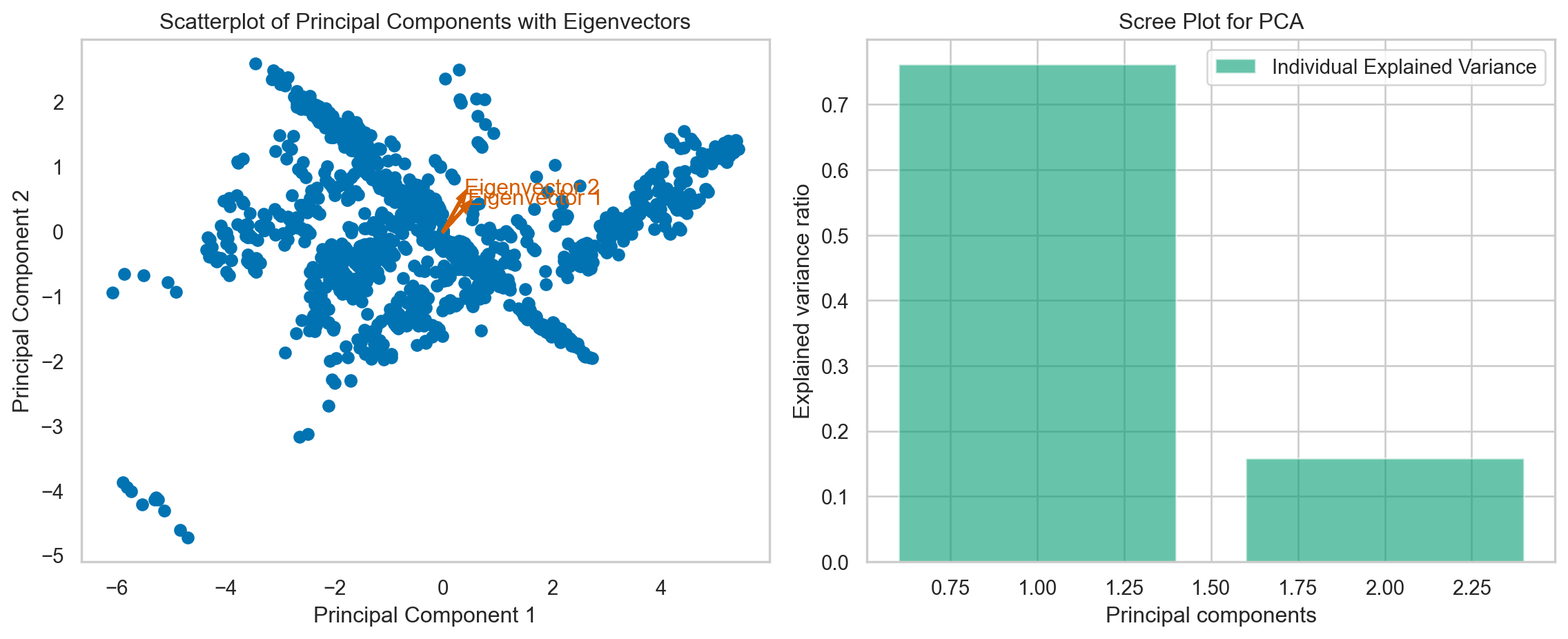
…Not really
Find the optimal number of components.
Code
# Assuming hfi DataFrame is already defined and loaded
# Select numerical columns
numerical_cols = hfi.select_dtypes(include=['int64', 'float64']).columns
# Scale the data
scaler = StandardScaler()
scaled_data = scaler.fit_transform(hfi[numerical_cols])
# Apply PCA
pca = PCA().fit(scaled_data)
# Get explained variance ratio and cumulative explained variance
explained_variance_ratio = pca.explained_variance_ratio_
cumulative_explained_variance = explained_variance_ratio.cumsum()
# Decide number of components to retain 75% variance
threshold = 0.75
num_components = next(i for i, cumulative_var in enumerate(cumulative_explained_variance) if cumulative_var >= threshold) + 1
# Plot the explained variance
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o', linestyle='--')
plt.axhline(y=threshold, color='r', linestyle='-')
plt.axvline(x=num_components, color='r', linestyle='-')
plt.annotate(f'{num_components} components', xy=(num_components, threshold), xytext=(num_components+5, threshold-0.05),
arrowprops=dict(color='r', arrowstyle='->'),
fontsize=12, color='r')
plt.title('Cumulative Explained Variance by Principal Components')
plt.xlabel('Principal Component')
plt.ylabel('Cumulative Explained Variance')
plt.grid(True)
plt.show()
print(f"Number of components to retain 75% variance: {num_components}")
# Apply PCA with the chosen number of components
pca = PCA(n_components=num_components)
reduced_data = pca.fit_transform(scaled_data)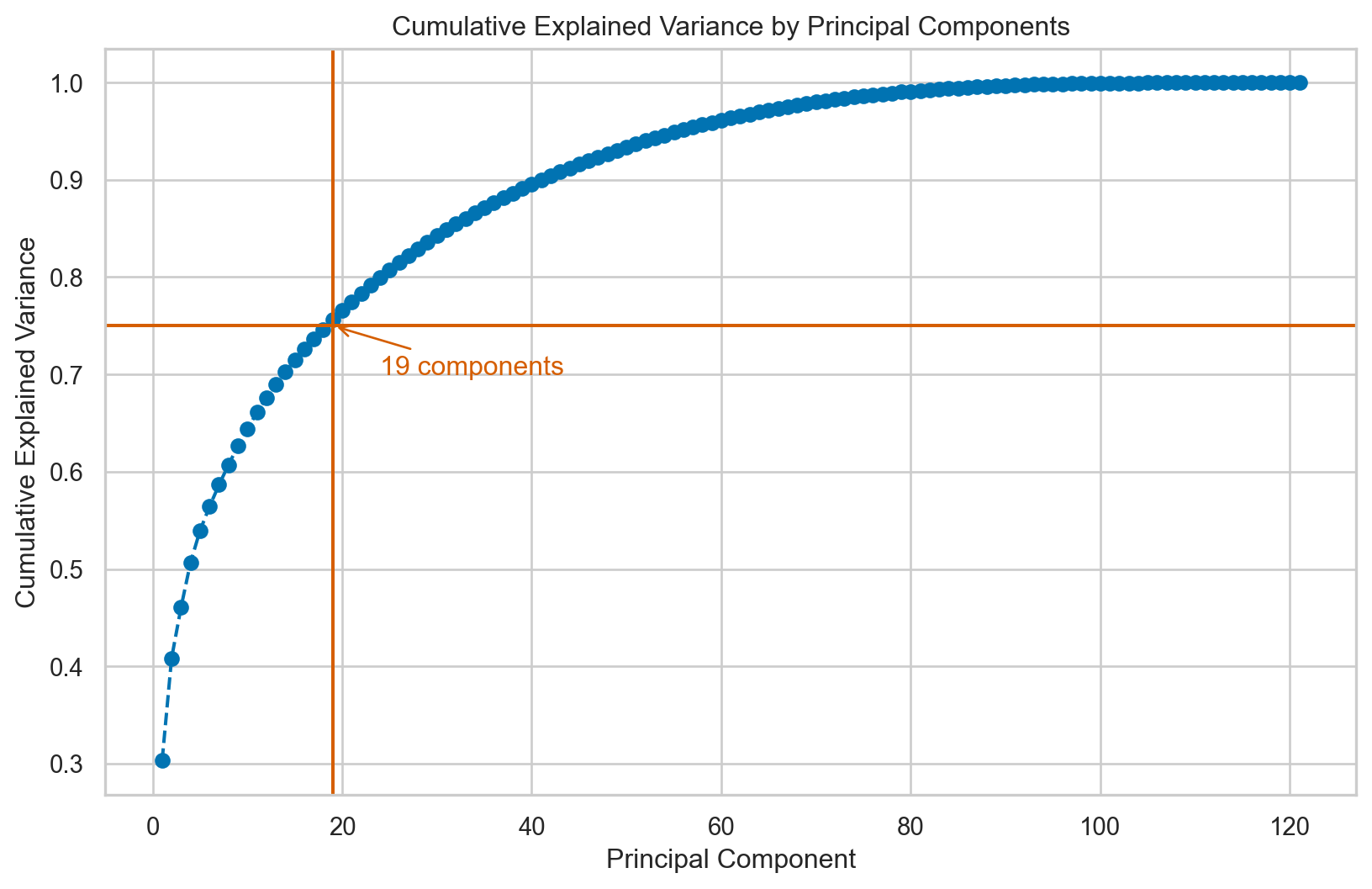
Number of components to retain 75% variance: 19
Clustering
K-Means Clustering
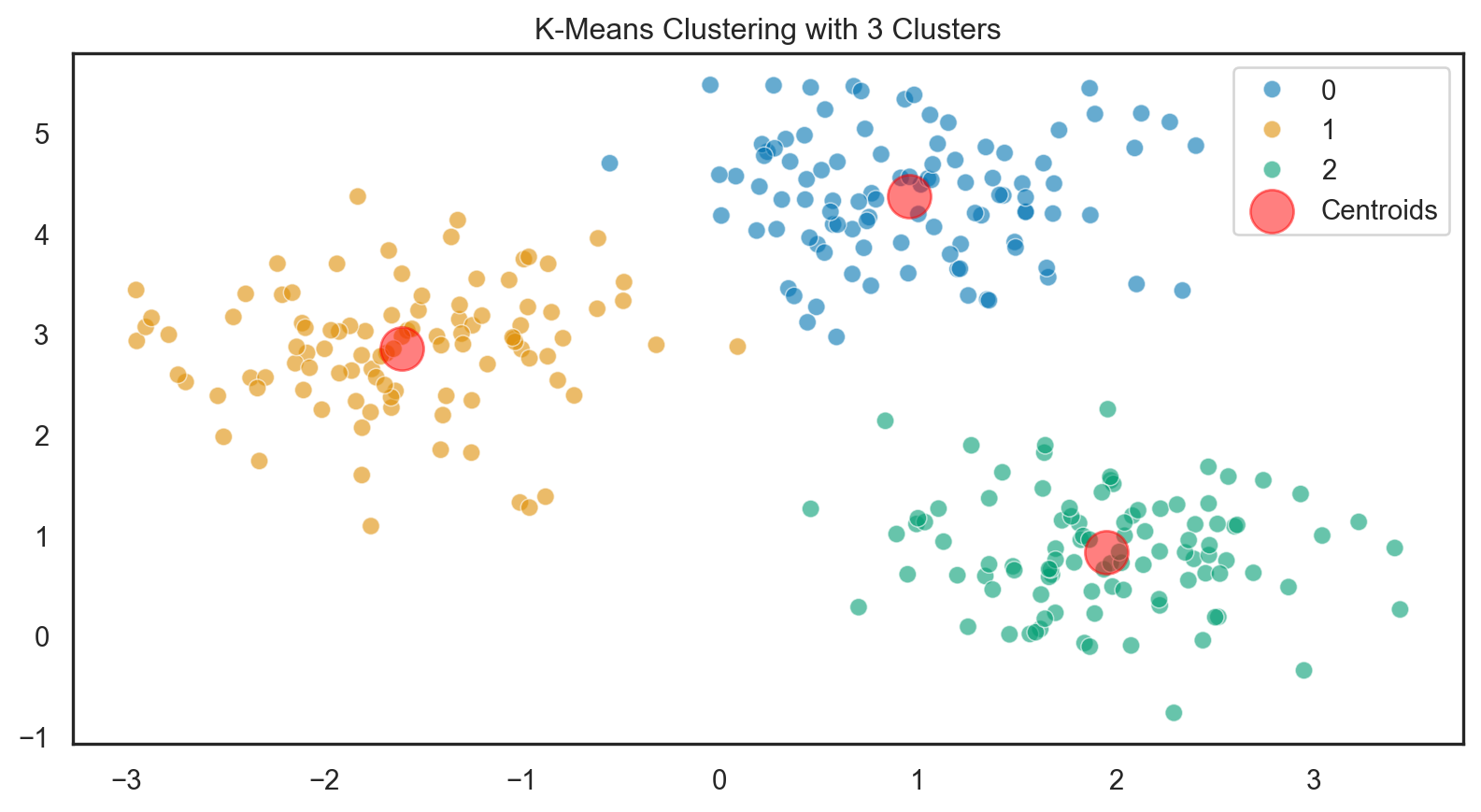
The goal of K-Means is to minimize the variance within each cluster. The variance is measured as the sum of squared distances between each point and its corresponding cluster centroid. The objective function, which K-Means aims to minimize, can be defined as:
\(J = \sum_{i=1}^{k} \sum_{x \in C_i} ||x - \mu_i||^2\)
Where:
\(J\) is the objective function
\(k\) is the number of clusters
\(C_i\) is the set of points belonging to a cluster \(i\).
\(x\) is a point in the cluster \(C_i\)
\(||x - \mu_i||^2\) is the squared Euclidean distance between a point \(x\) and the centroid \(\mu_i\), which measures the dissimilarity between them.
Initialization: Randomly selects \(k\) initial centroids.
Assignment Step: Assigns each data point to the closest centroid based on Euclidean distance.
Update Step: Recalculates centroids as the mean of assigned points in each cluster.
Convergence: Iterates until the centroids stabilize (minimal change from one iteration to the next).
Objective: Minimizes the within-cluster sum of squares (WCSS), the sum of squared distances between points and their corresponding centroid.
Optimal \(k\): Determined experimentally, often using methods like the Elbow Method.
Sensitivity: Results can vary based on initial centroid selection; techniques like “k-means++” improve initial centroid choices.
Efficiency: Generally good, but worsens with increasing \(k\) and data dimensionality; sensitive to outliers.
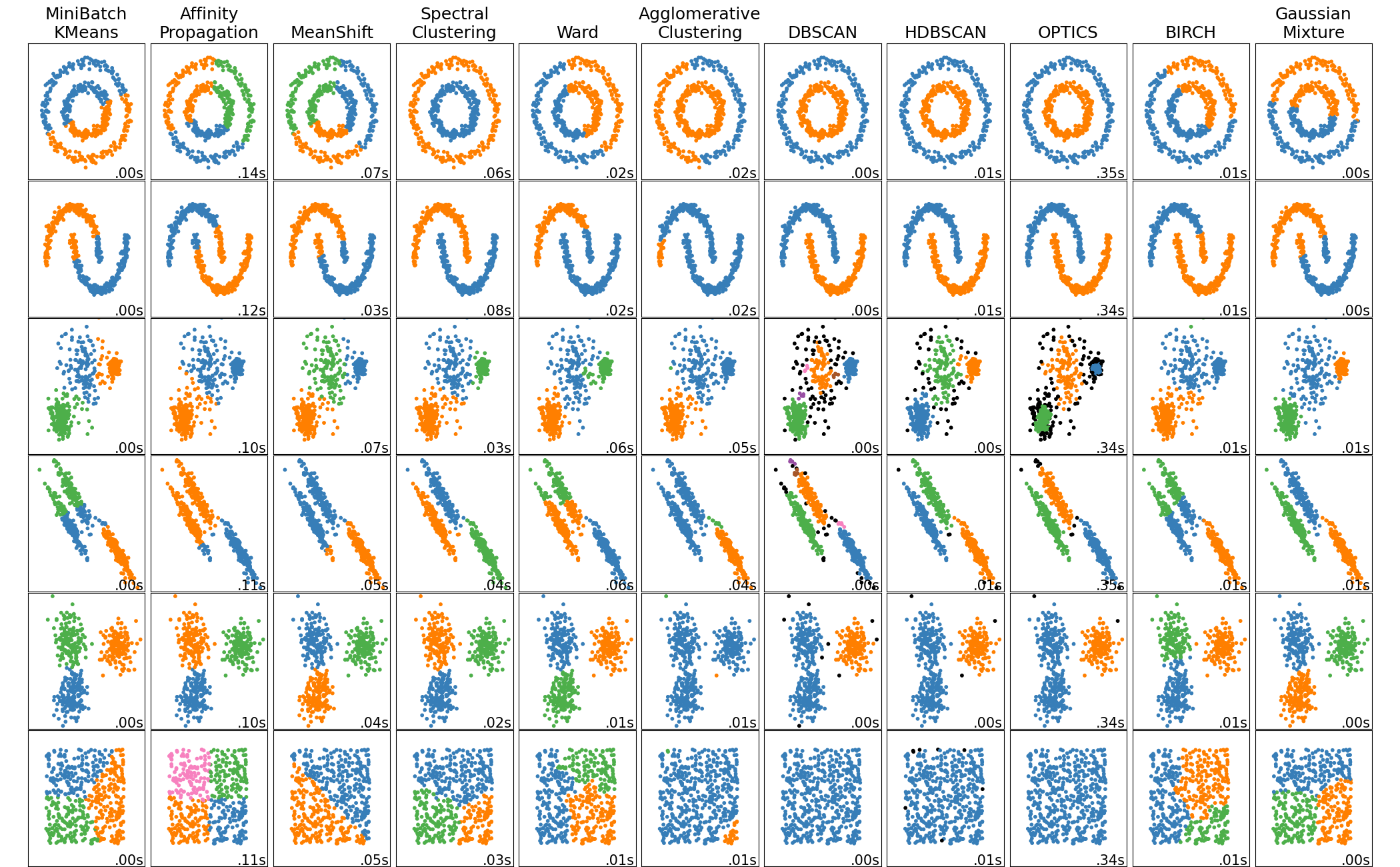
Systematic comparison: Equal clusters
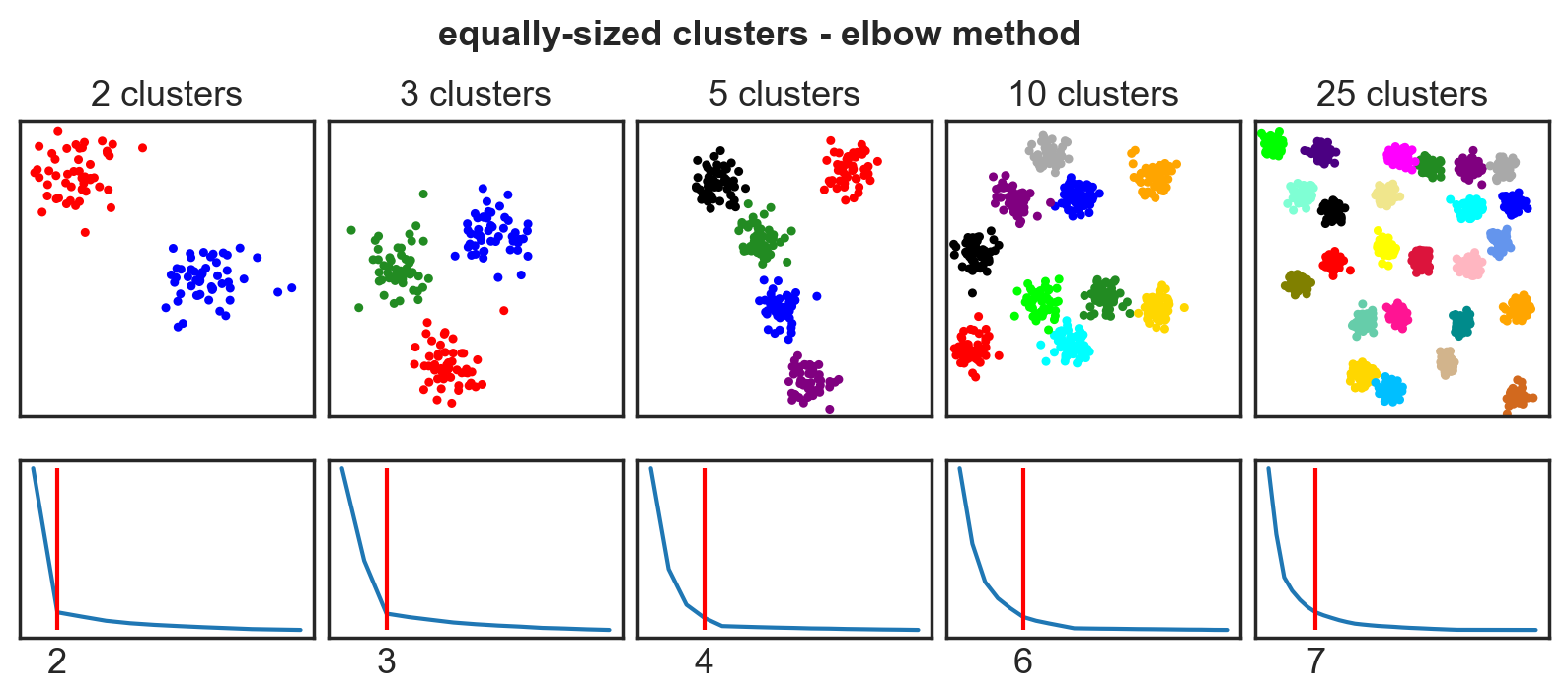
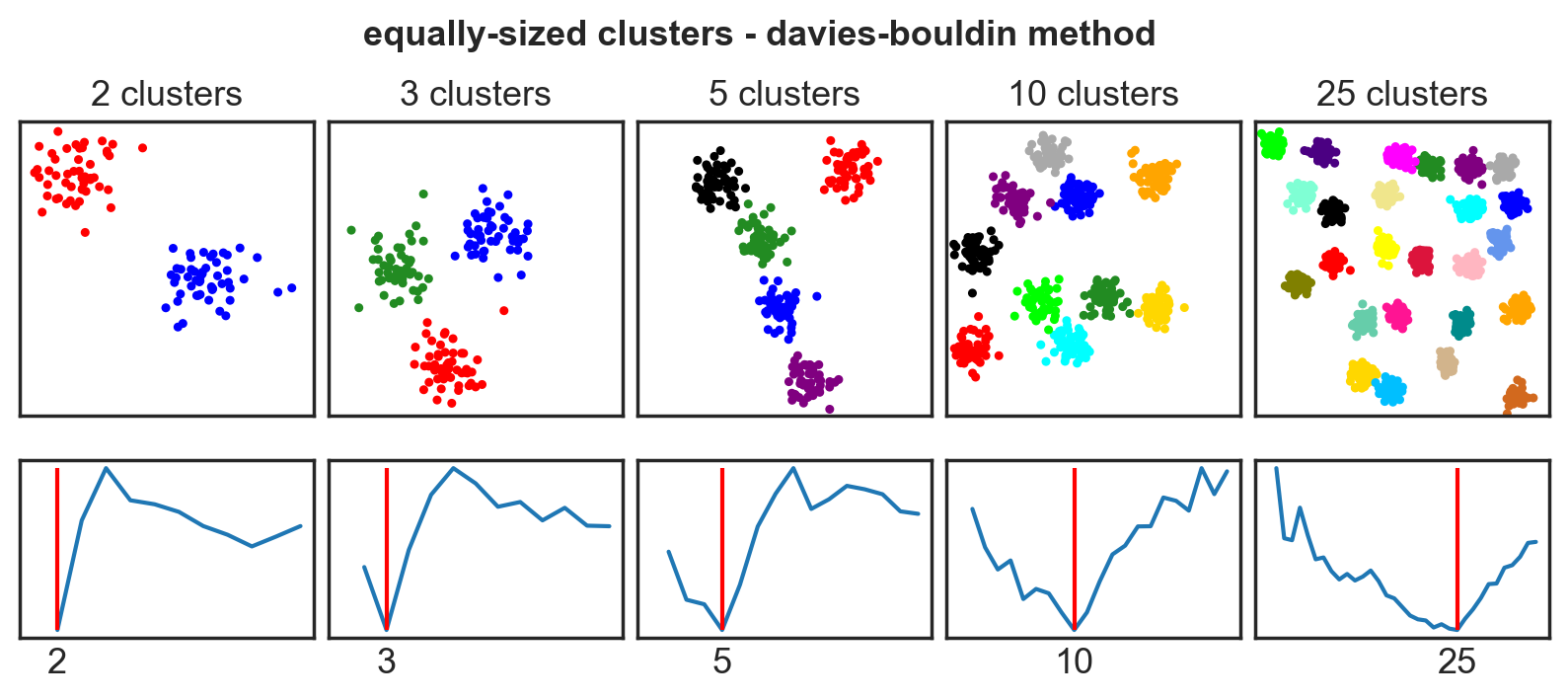
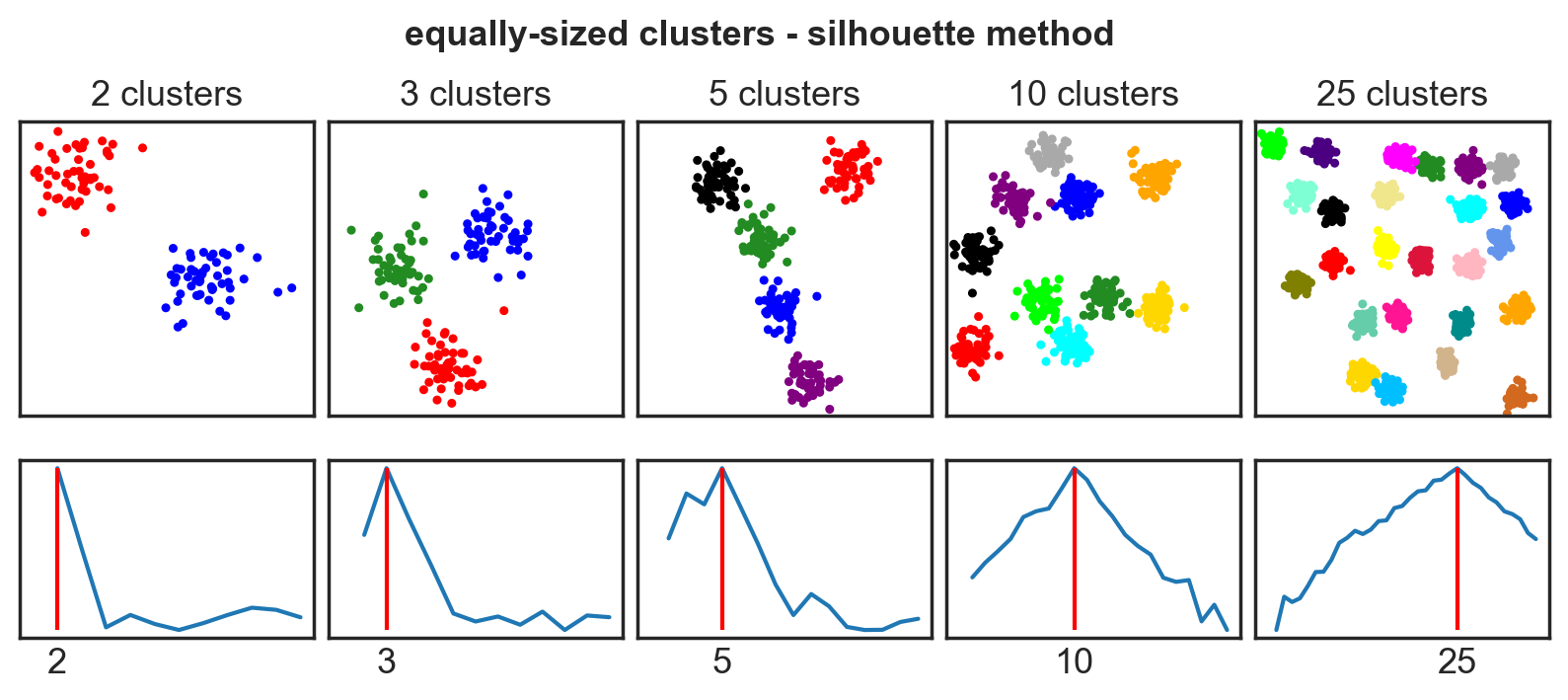
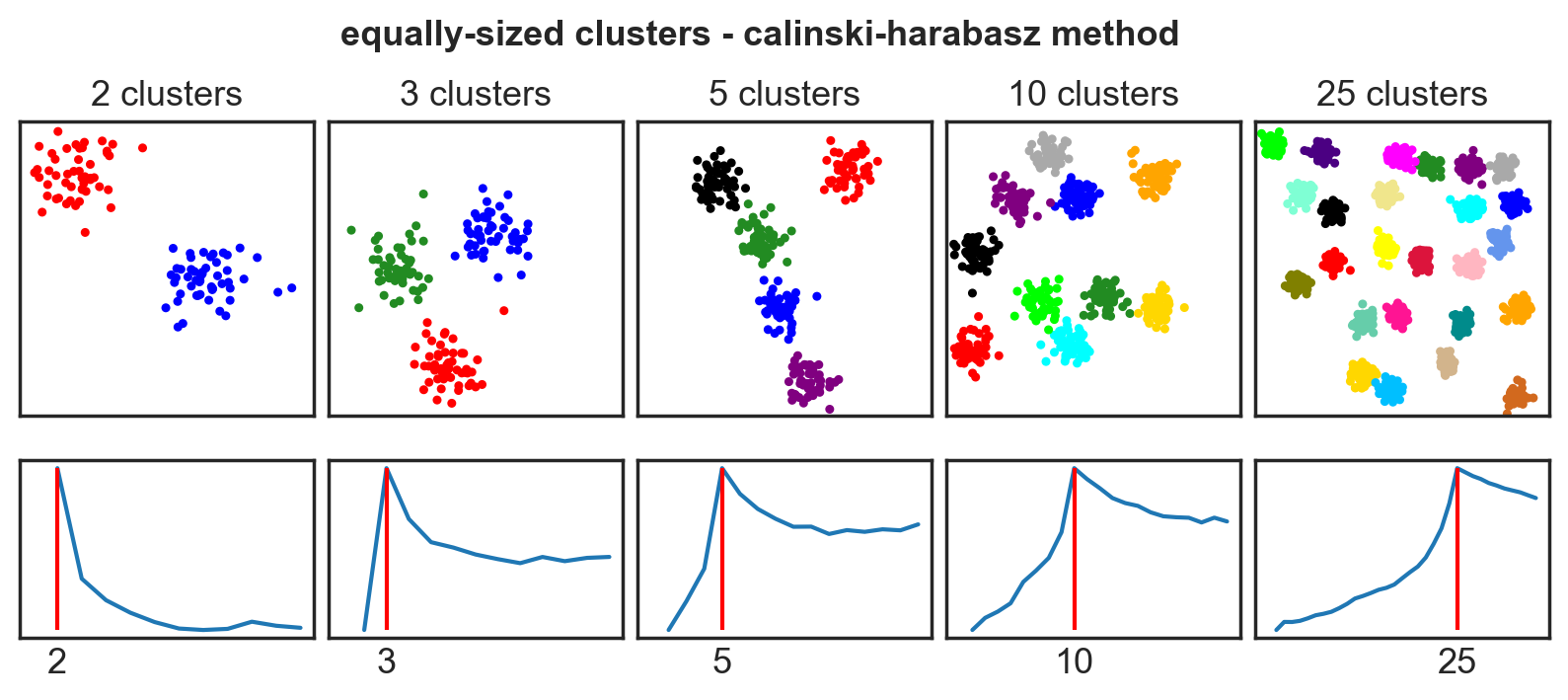
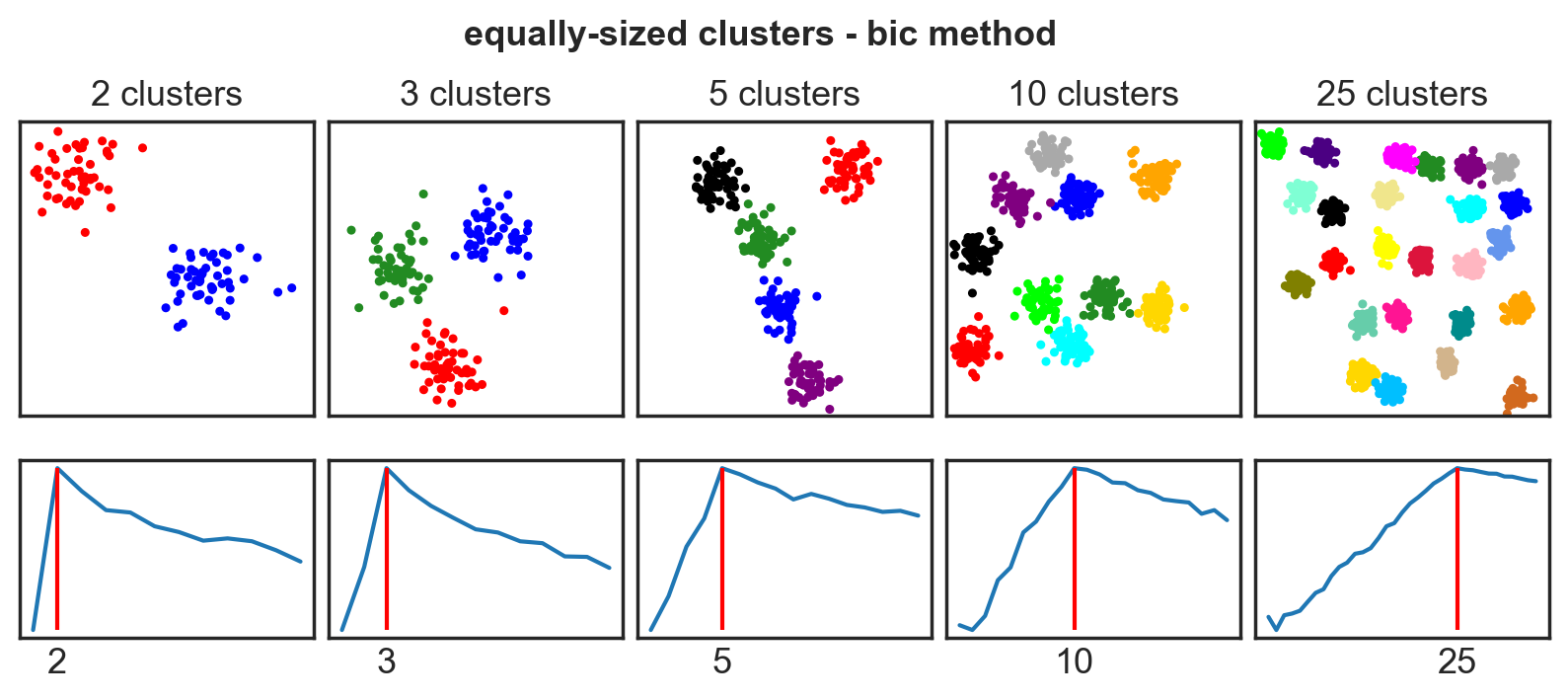
Systematic comparison: Unequal clusters
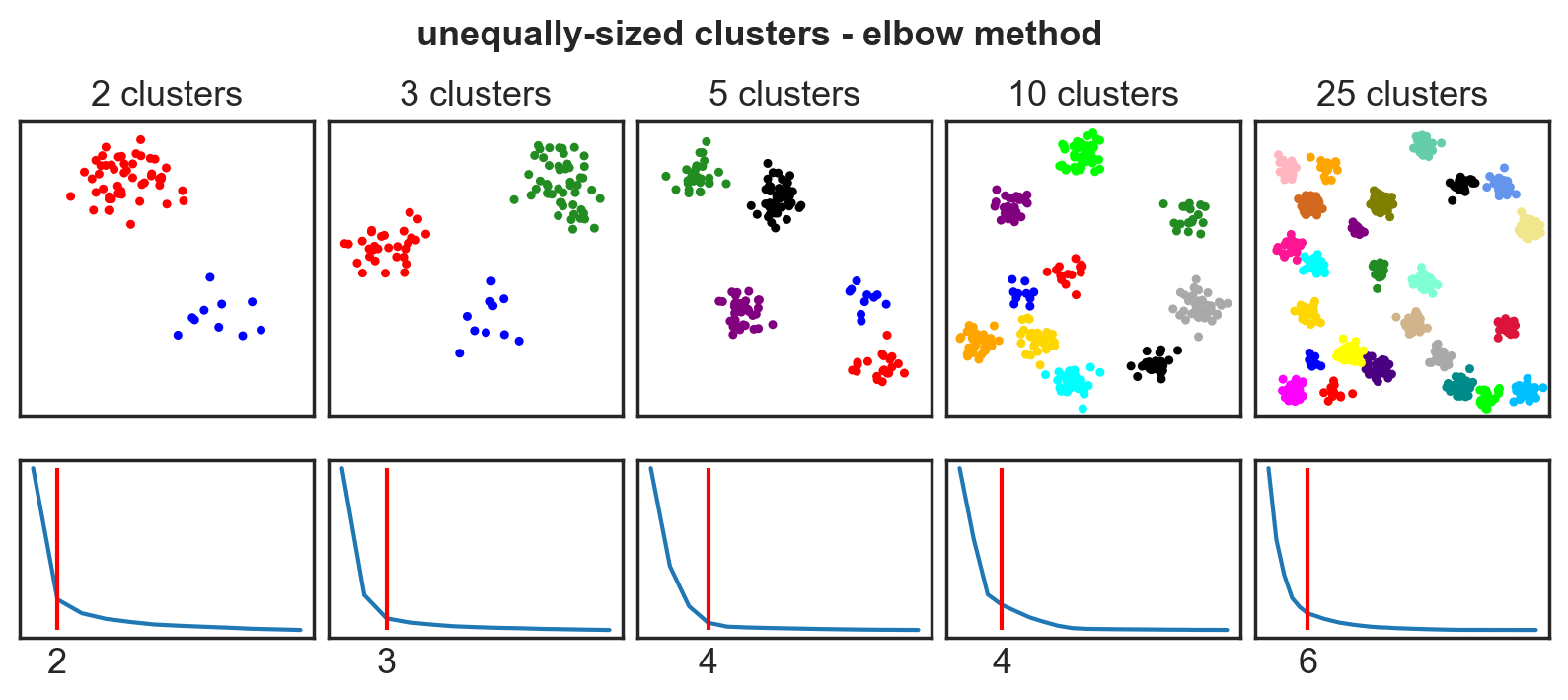
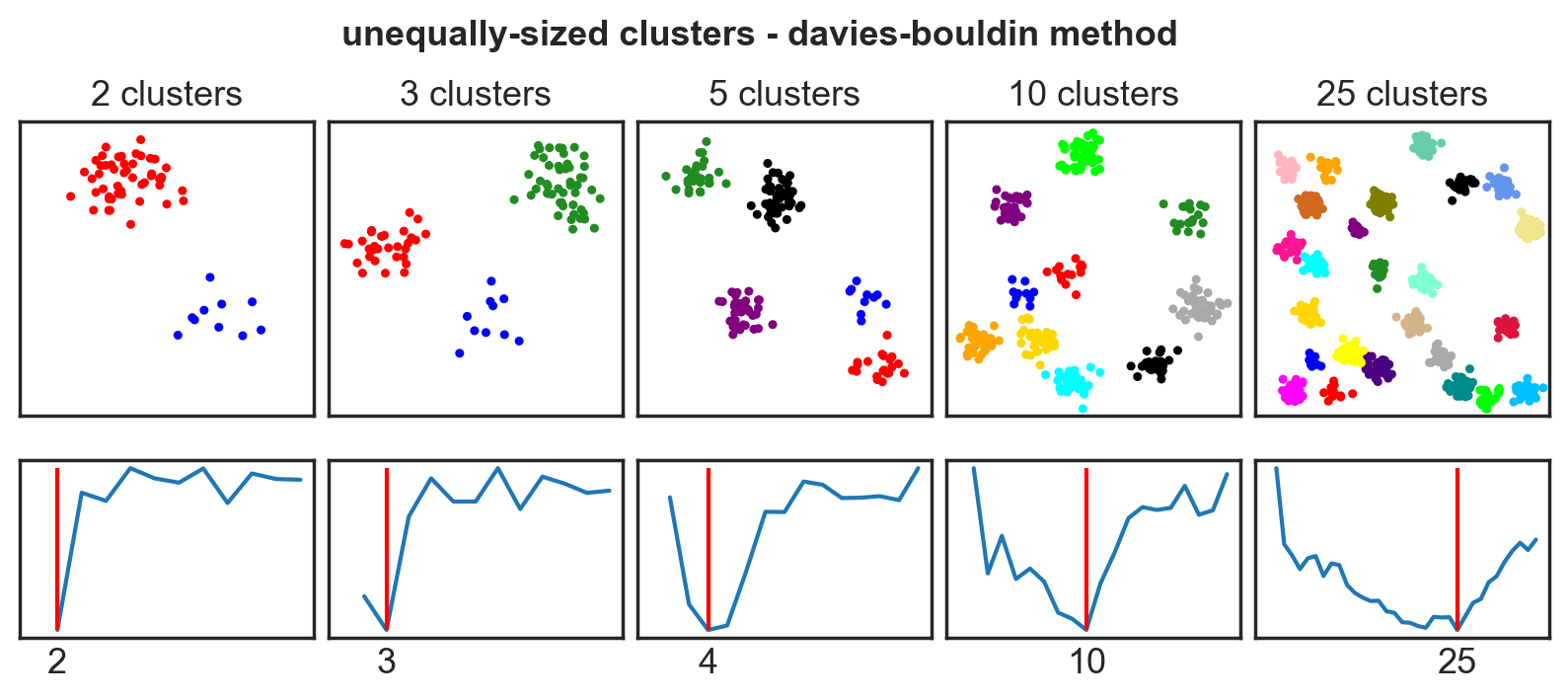
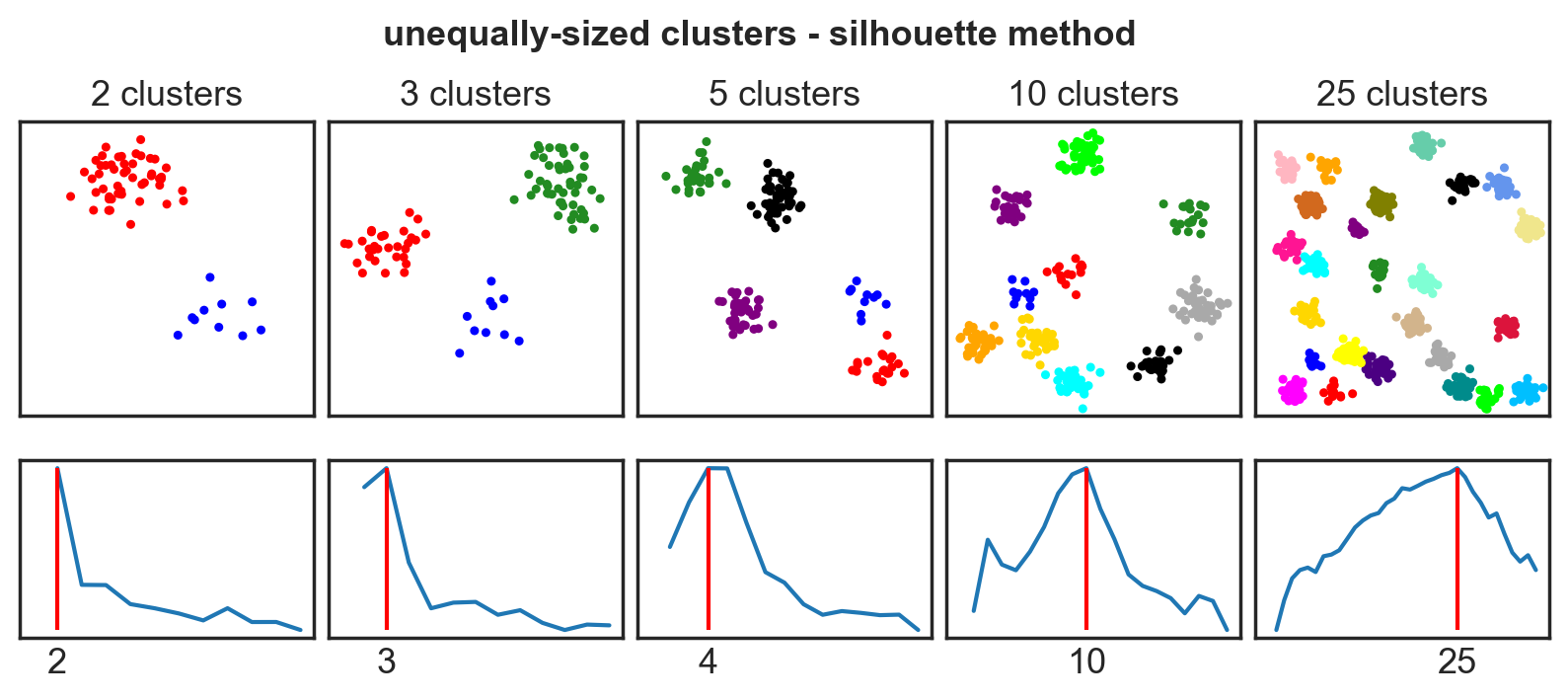
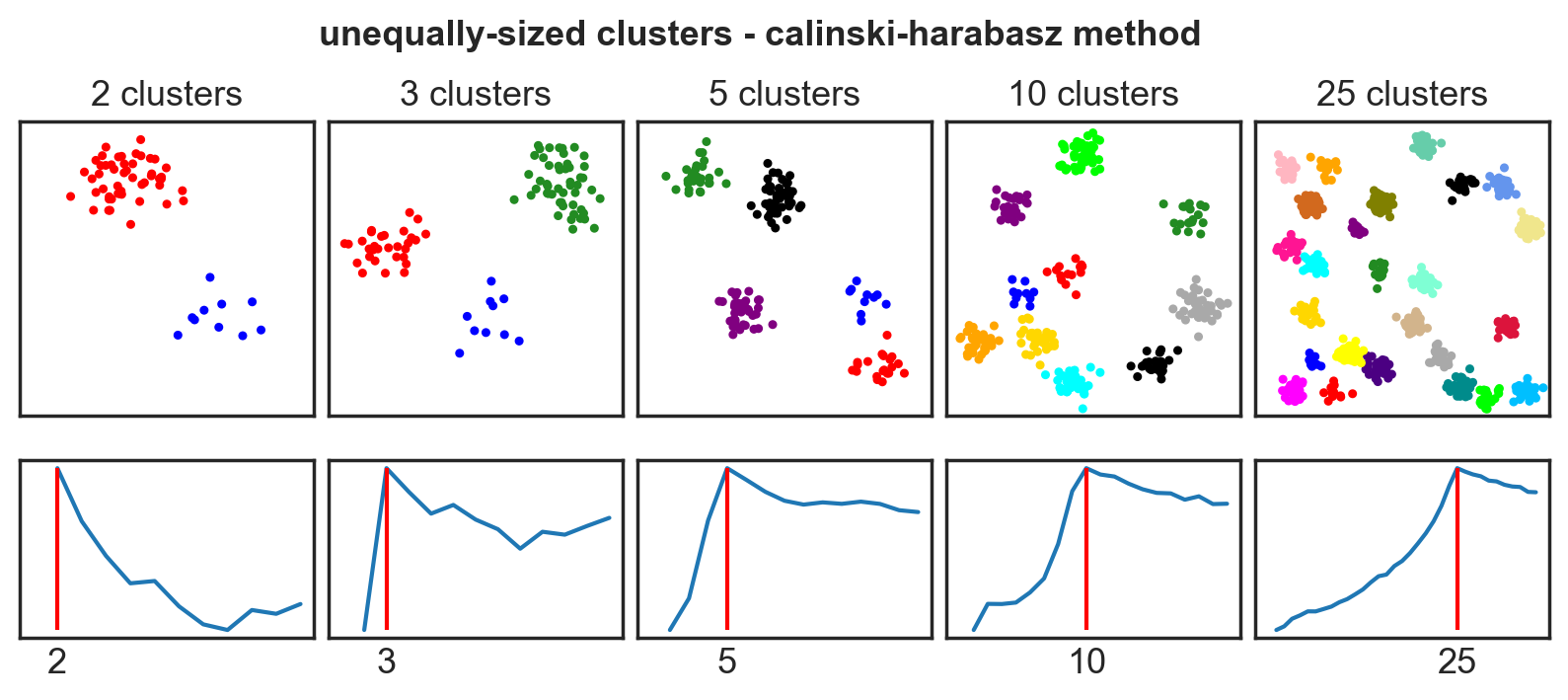
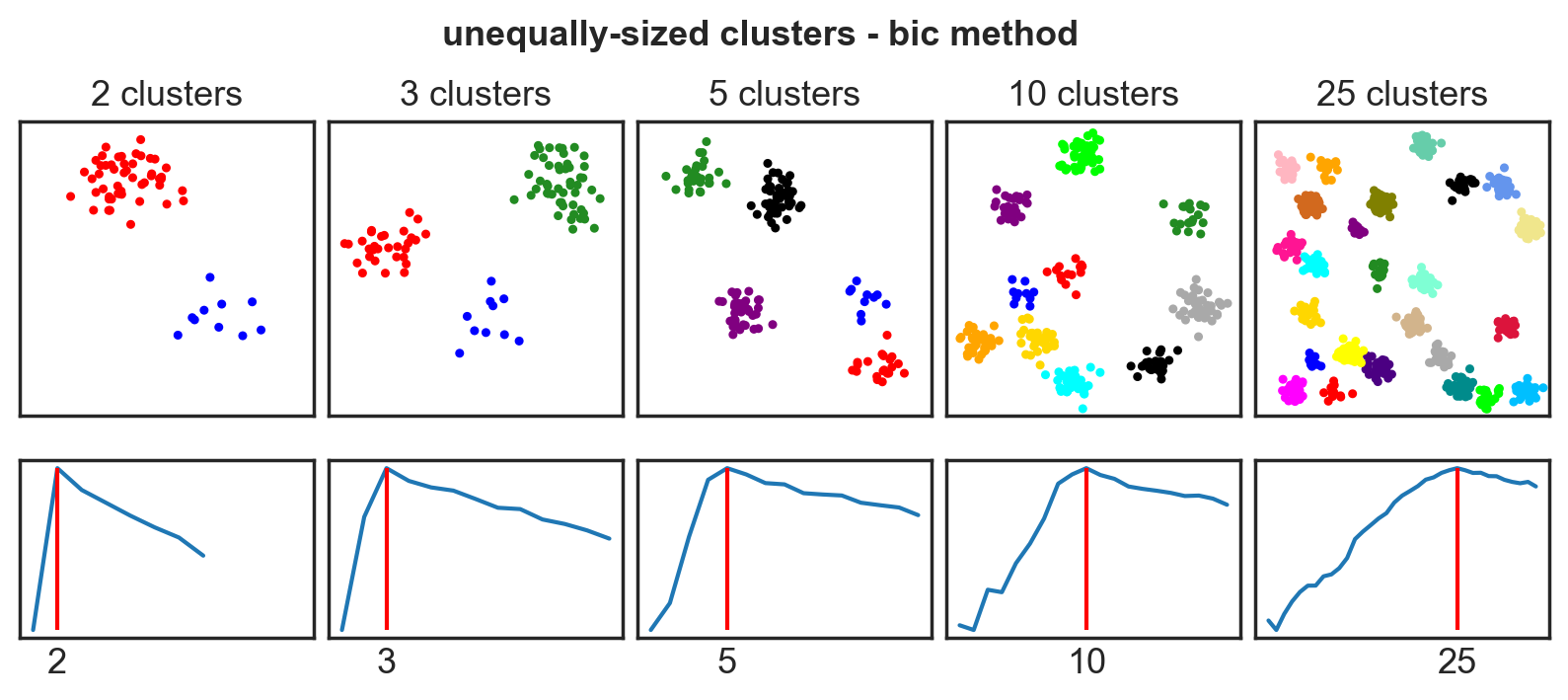
Systematic comparison - accuracy
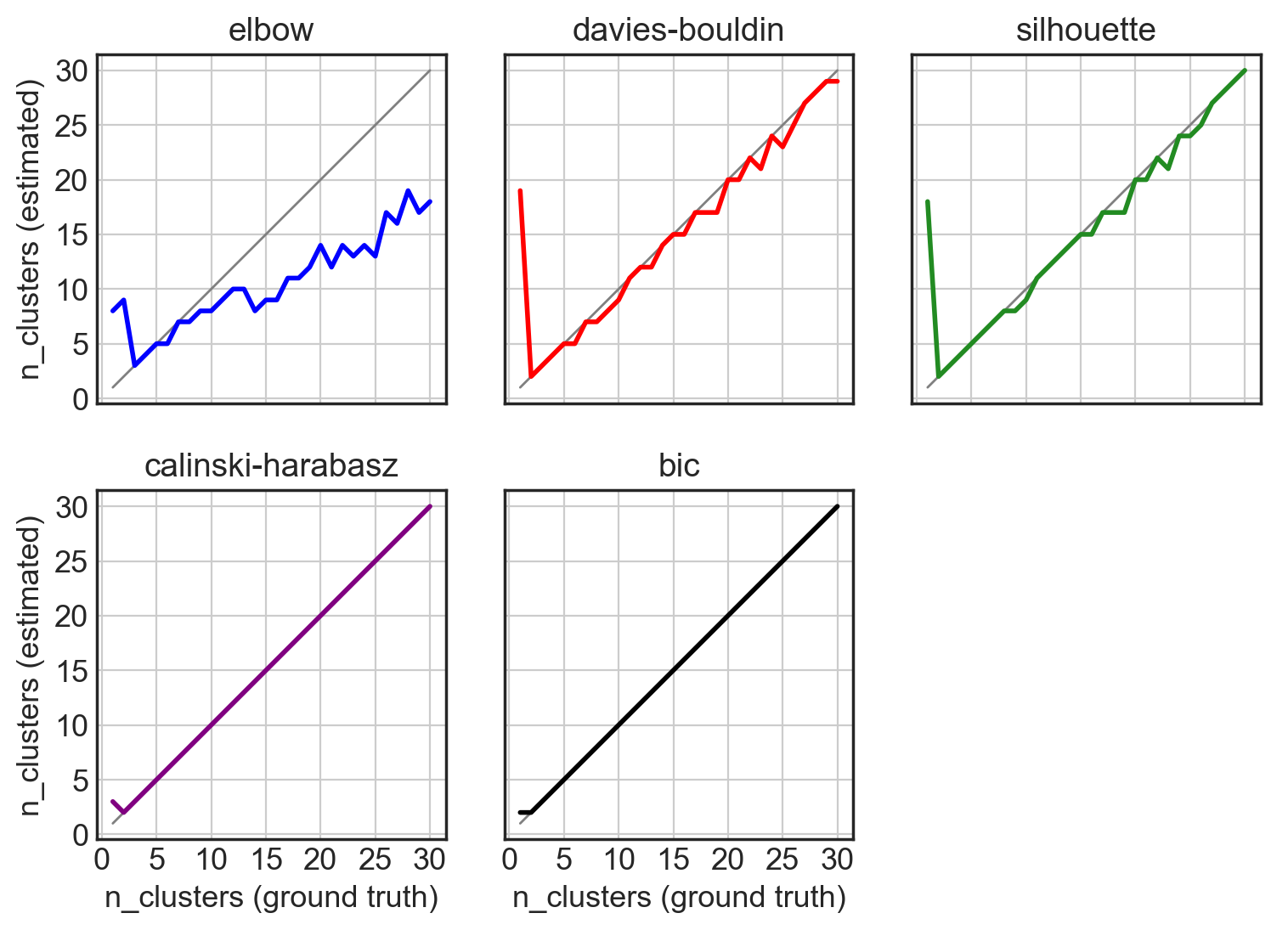
Calinski-Harabasz Index
\(CH = \frac{SS_B / (k - 1)}{SS_W / (n - k)}\)
where:
\(CH\) is the Calinski-Harabasz score.
\(SS_B\) is the between-cluster variance.
\(SS_W\) is the within-cluster variance.
\(k\) is the number of clusters.
\(n\) is the number of data points.
Pros:
Clear Interpretation: High values indicate better-defined clusters.
Computationally Efficient: Less resource-intensive than many alternatives.
Scale-Invariant: Effective across datasets of varying sizes.
No Labeled Data Required: Useful for unsupervised learning scenarios.
Cons:
Cluster Structure Bias: Prefers convex clusters of similar sizes.
Sample Size Sensitivity: Can favor more clusters in larger datasets.
Not Ideal for Overlapping Clusters: Assumes distinct, non-overlapping clusters.
BIC
\(\text{BIC} = -2 \ln(\hat{L}) + k \ln(n)\)
where:
\(\hat{L}\) is the maximized value of the likelihood function of the model,
\(k\) is the number of parameters in the model,
\(n\) is the number of observations.
Pros:
Penalizes Complexity: Helps avoid overfitting by penalizing models with more parameters.
Objective Selection: Facilitates choosing the model with the best balance between fit and simplicity.
Applicability: Useful across various model types, including clustering and regression.
Cons:
Computationally Intensive: Requires fitting multiple models to calculate, which can be resource-heavy.
Sensitivity to Model Assumptions: Performance depends on the underlying assumptions of the model being correct.
Not Always Intuitive: Determining the absolute best model may still require domain knowledge and additional diagnostics.
K-Means Clustering: applied
Code
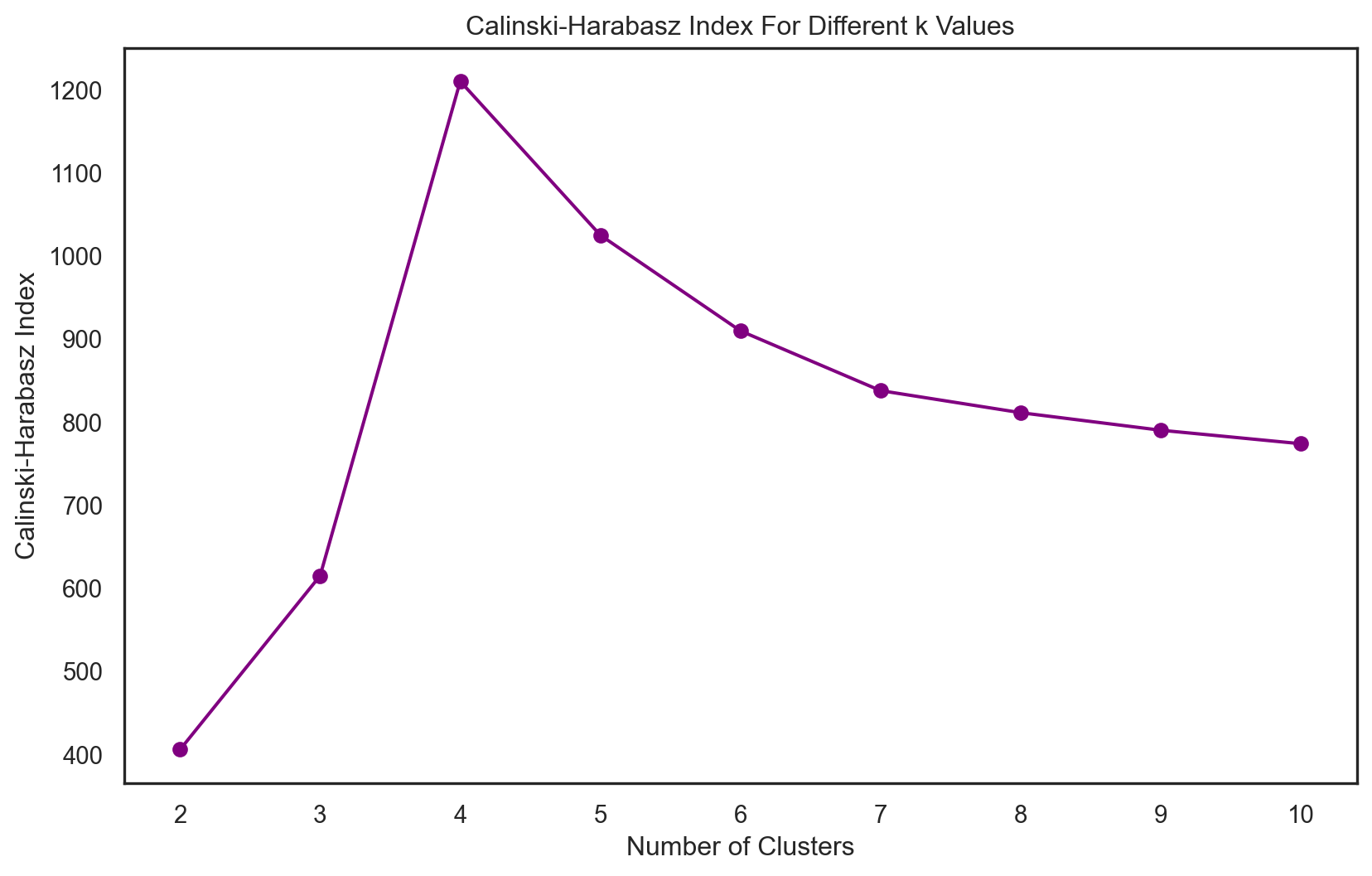
# Finding the optimal number of clusters using Calinski-Harabasz Index
calinski_harabasz_scores = []
cluster_range = range(2, 11) # Define the range for number of clusters
for n_clusters in cluster_range:
kmeans = KMeans(n_clusters=n_clusters, random_state=0)
kmeans.fit(data)
labels = kmeans.labels_
score = calinski_harabasz_score(data, labels)
calinski_harabasz_scores.append(score)
# Plotting the Calinski-Harabasz scores
plt.plot(cluster_range, calinski_harabasz_scores, marker='o')
plt.title('Calinski-Harabasz Index for Different Numbers of Clusters')
plt.xlabel('Number of Clusters')
plt.ylabel('Calinski-Harabasz Index')
plt.grid(True)
plt.show()
# Finding the number of clusters that maximizes the Calinski-Harabasz Index
optimal_n_clusters = cluster_range[calinski_harabasz_scores.index(max(calinski_harabasz_scores))]
print(f"The optimal number of clusters is: {optimal_n_clusters}")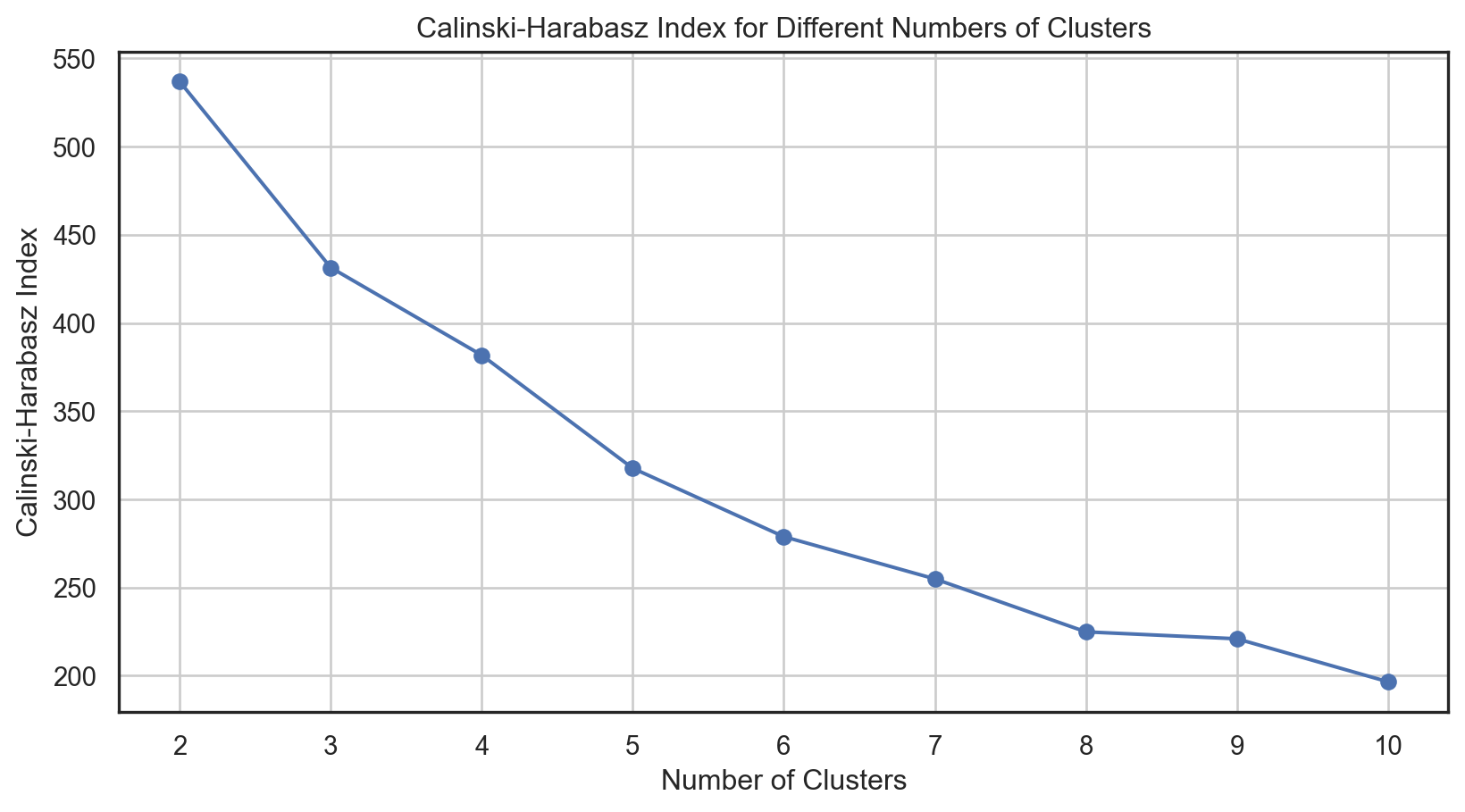
The optimal number of clusters is: 2Code
# K-Means Clustering with the optimal number of clusters
kmeans = KMeans(n_clusters=optimal_n_clusters, random_state=0)
kmeans.fit(data)
clusters = kmeans.predict(data)
# Adding cluster labels to the DataFrame
data['Cluster'] = clusters
# Model Summary
print("Cluster Centers:\n", kmeans.cluster_centers_)
# Evaluate clustering performance using the Calinski-Harabasz Index
calinski_harabasz_score_final = calinski_harabasz_score(data.drop(columns='Cluster'), clusters)
print(f"For n_clusters = {optimal_n_clusters}, the Calinski-Harabasz Index is : {calinski_harabasz_score_final:.3f}")Cluster Centers:
[[ 6.81306346 0.19993757 -0.28806769 -0.29502272 -0.46716703 0.05454598
-0.12994433 0.03657521 -0.02176455 0.03151719 0.24393655 -0.01449253
-0.03272898 0.04760448 -0.01648803 -0.03251455 0.01440017 0.05300893
-0.01630804]
[-3.57757098 -0.10498814 0.15126567 0.15491779 0.24531156 -0.02864235
0.06823436 -0.01920581 0.01142867 -0.01654982 -0.12809221 0.0076101
0.01718614 -0.02499733 0.00865794 0.01707354 -0.00756159 -0.02783523
0.00856343]]
For n_clusters = 2, the Calinski-Harabasz Index is : 536.957Code
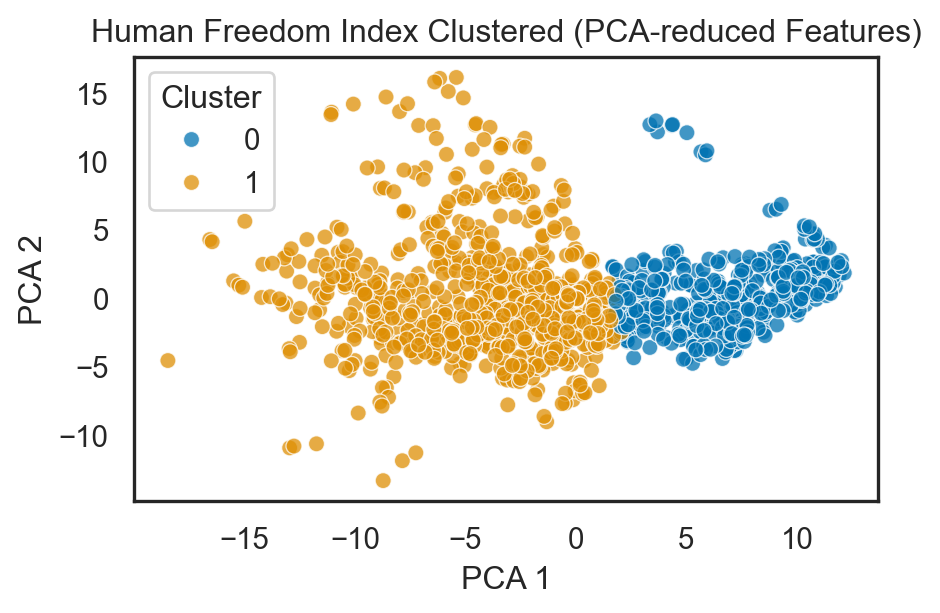
pca = PCA(n_components = 2)
reduced_data_PCA = pca.fit_transform(data)
sns.scatterplot(x = reduced_data_PCA[:, 0], y = reduced_data_PCA[:, 1], hue = clusters, alpha = 0.75, palette = "colorblind")
plt.title('Human Freedom Index Clustered (PCA-reduced Features)')
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.legend(title = 'Cluster')
plt.show()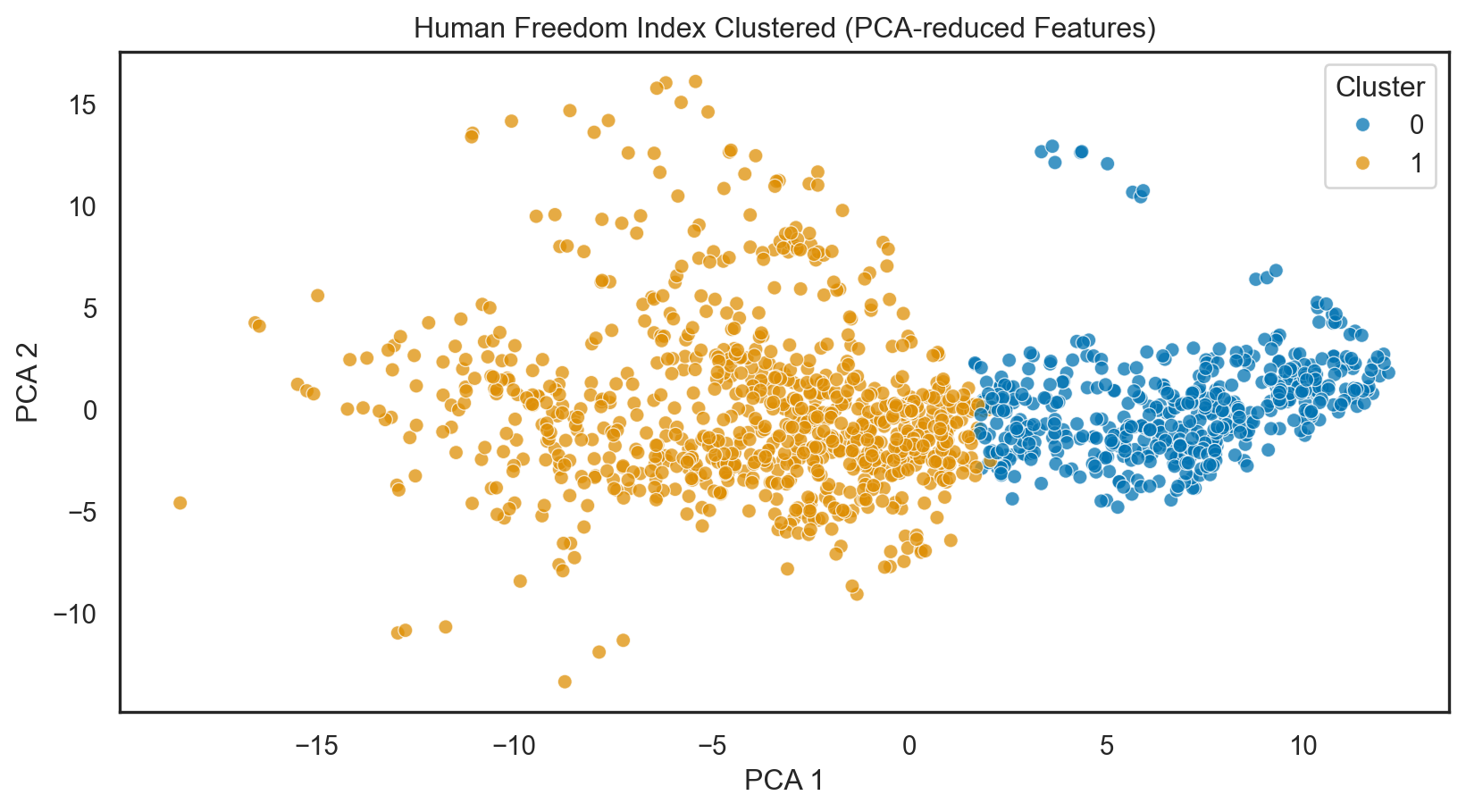
Caveat