import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.dates import DateFormatter
import matplotlib.dates as mdates
from janitor import clean_names
# Set the theme for seaborn
sns.set_theme(style="white", palette="colorblind")
# Set figure parameters
plt.rcParams['figure.figsize'] = [8, 8 * 0.618]
plt.rcParams['figure.autolayout'] = TrueTime Series Visualizations
INFO Data Visualization and Analysis - Week 4
Air Quality Index
The AQI is the Environmental Protection Agency’s index for reporting air quality
Higher values of AQI indicate worse air quality

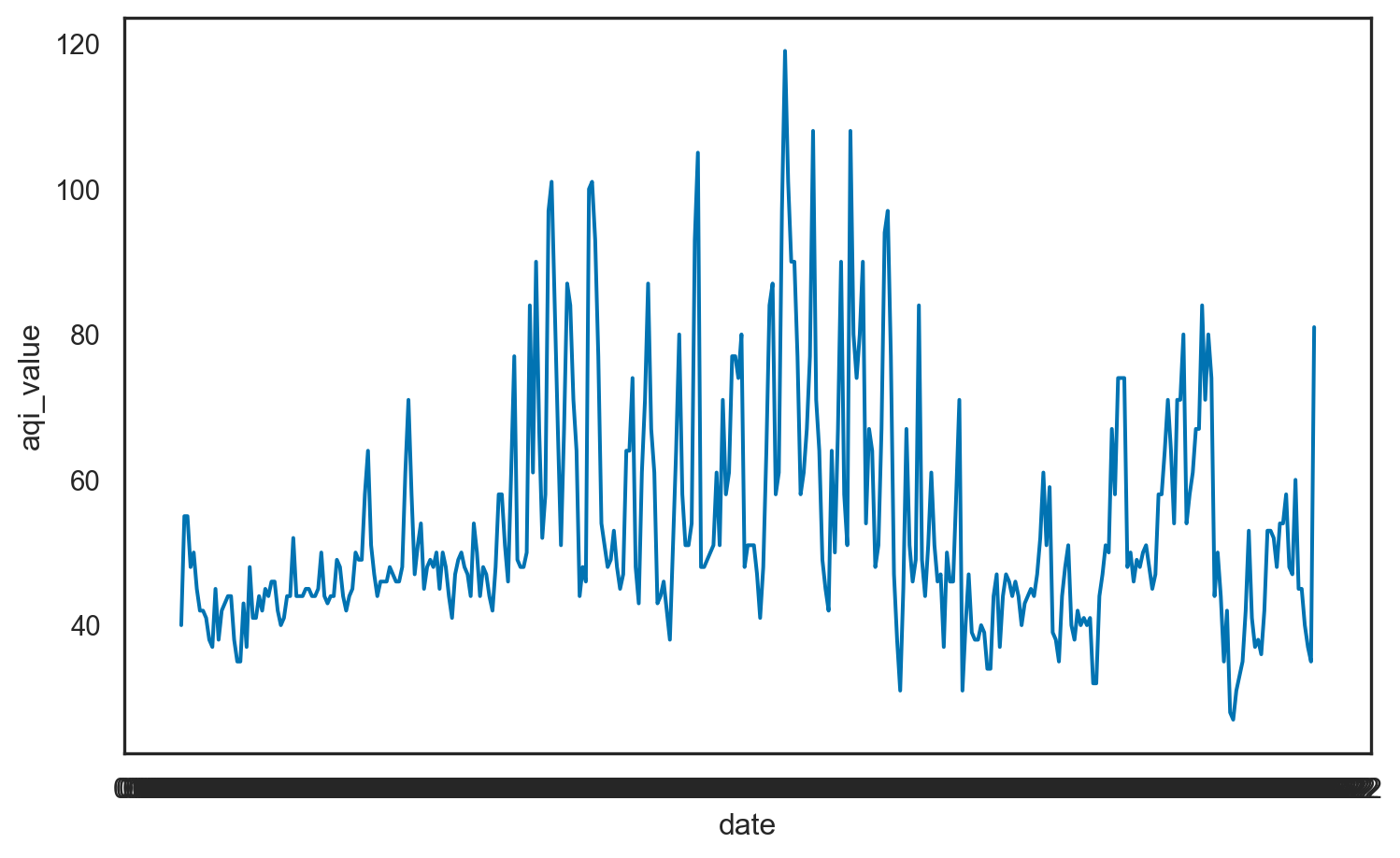
First look
This plot looks quite bizarre. What might be going on?
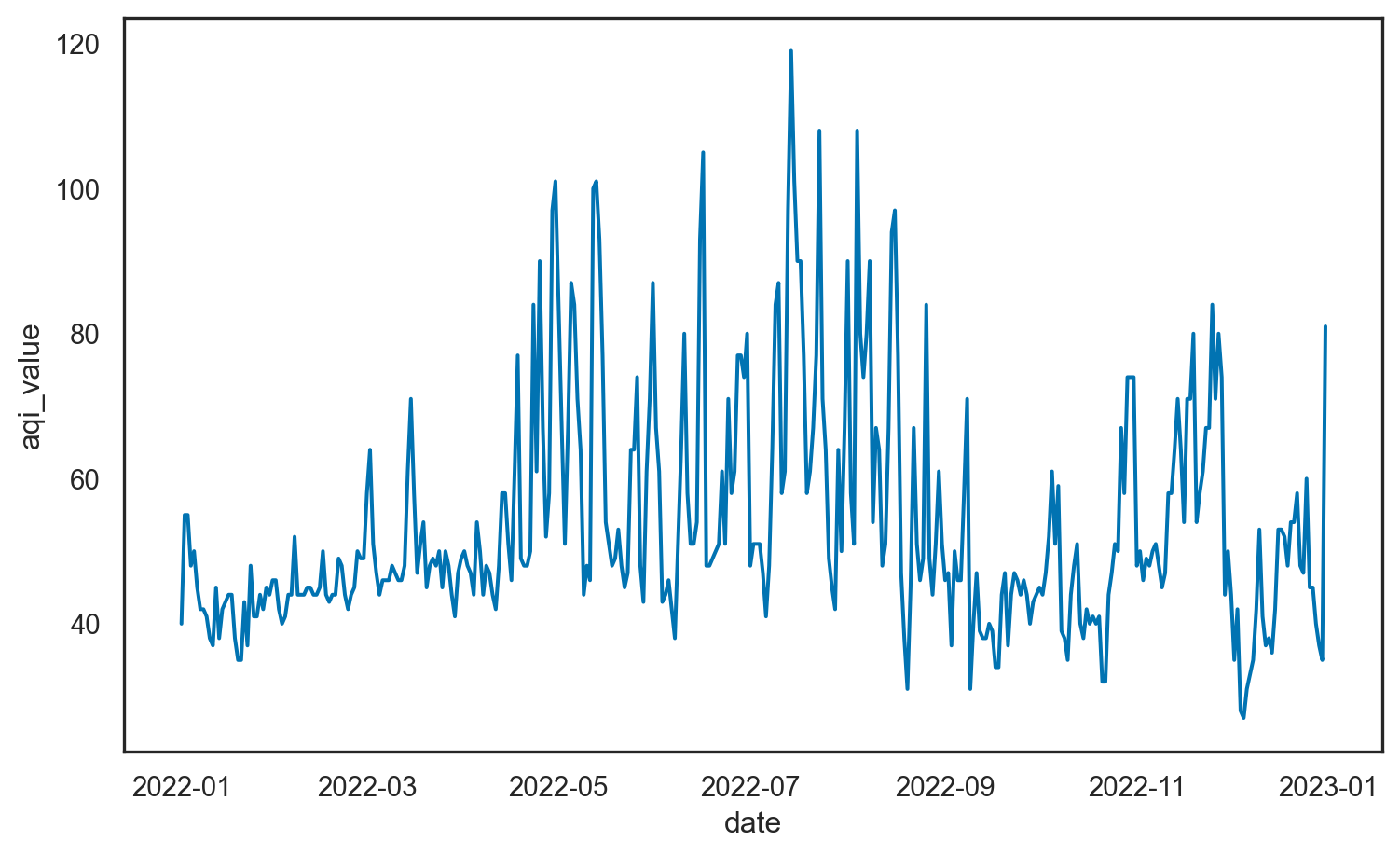
Another look
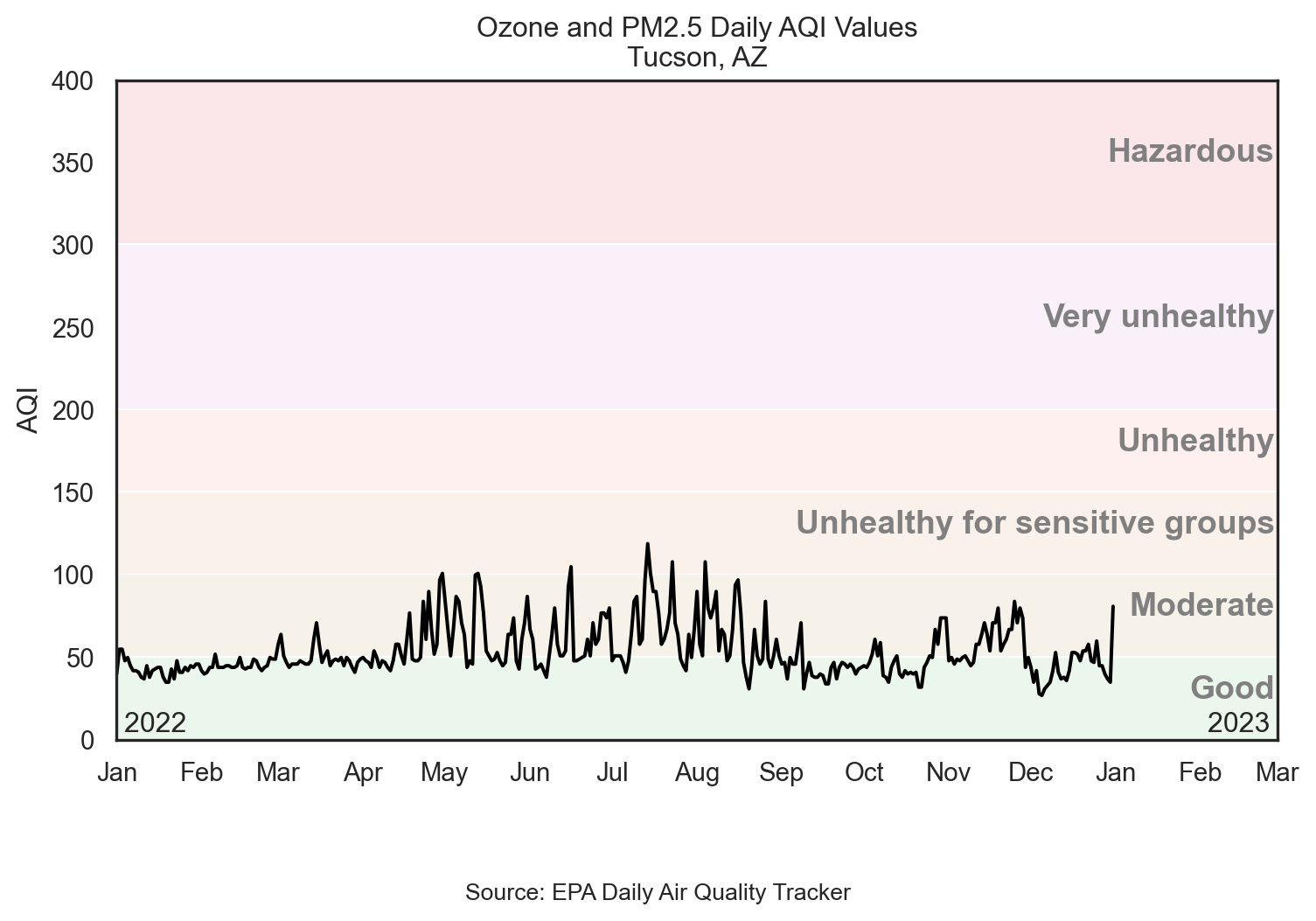
Visualizing Tucson AQI
Plotting cumulatives
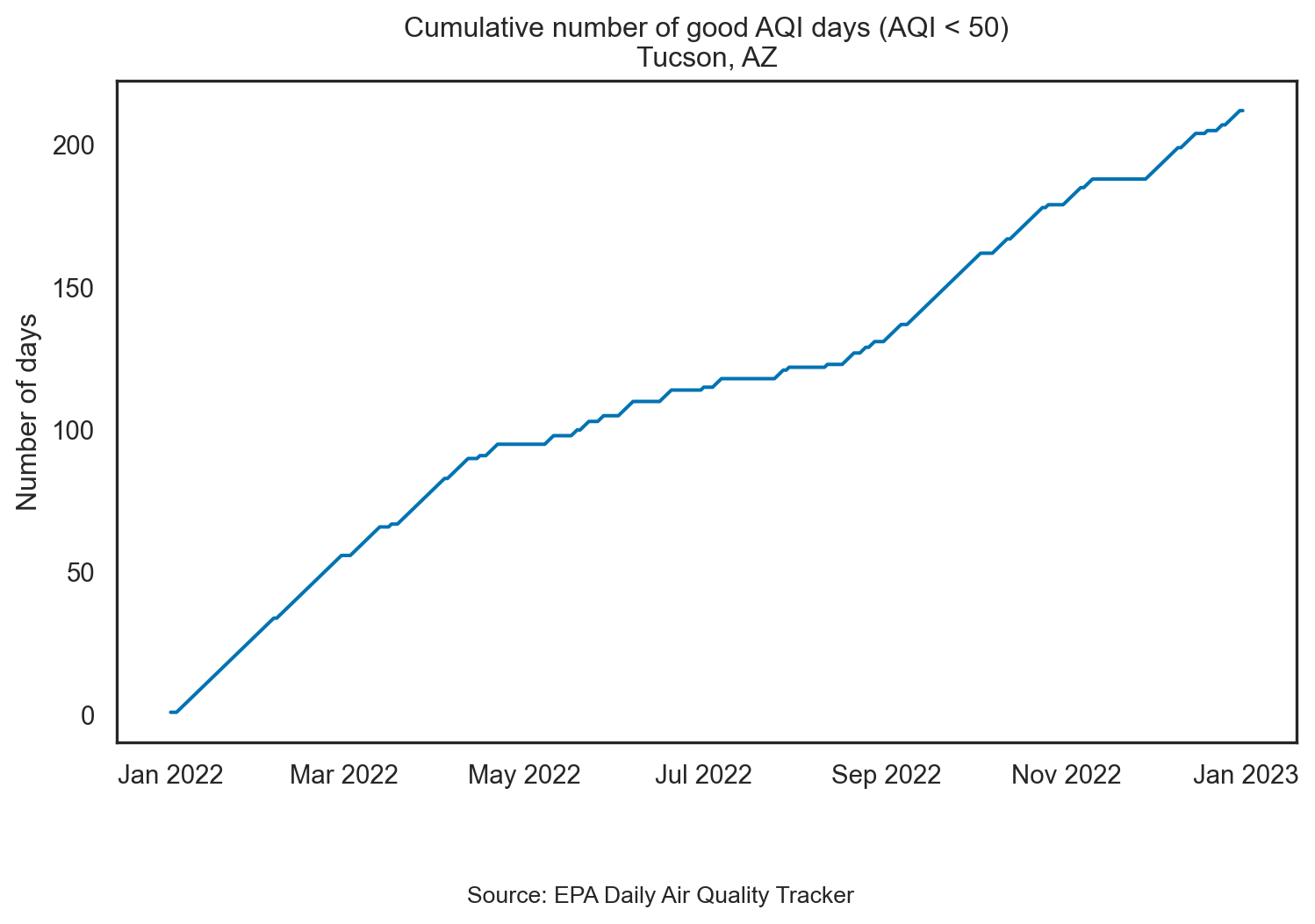
sns.lineplot(data=tuc_2022, x='date', y='cumsum_good_aqi')
plt.gca().xaxis.set_major_formatter(DateFormatter("%b %Y"))
plt.xlabel(None)
plt.ylabel("Number of days")
plt.title("Cumulative number of good AQI days (AQI < 50)\nTucson, AZ")
plt.figtext(0.5, -0.1, 'Source: EPA Daily Air Quality Tracker', ha='center', size=10)
plt.show()Plot trend since 2017
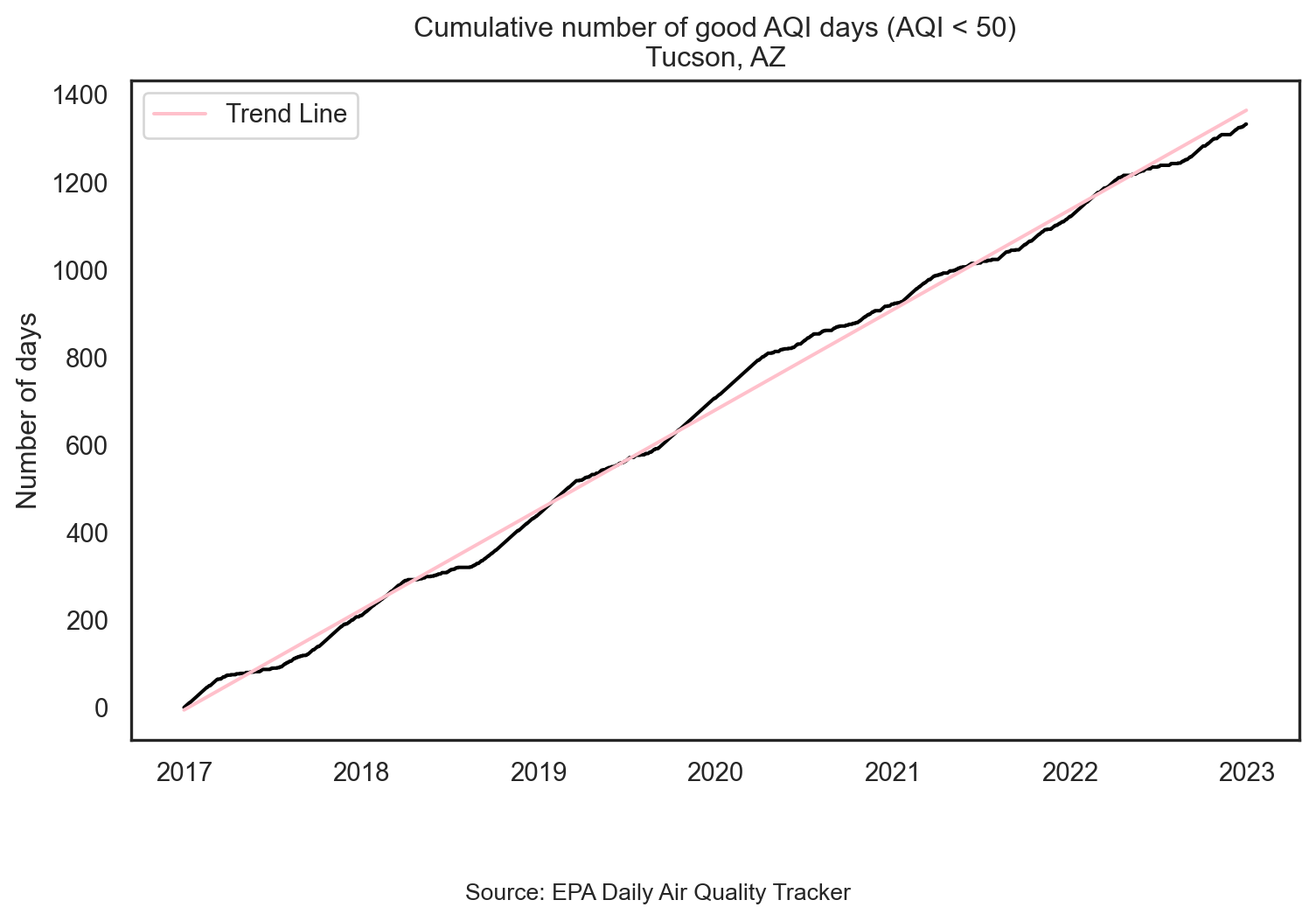
sns.lineplot(data=tuc, x='date', y='cumsum_good_aqi', color = 'black')
sns.lineplot(data=tuc, x='date', y='fitted', color='pink', label='Trend Line')
plt.gca().xaxis.set_major_formatter(DateFormatter("%Y"))
plt.xlabel(None)
plt.ylabel("Number of days")
plt.title("Cumulative number of good AQI days (AQI < 50)\nTucson, AZ")
plt.figtext(0.5, -0.1, 'Source: EPA Daily Air Quality Tracker', ha='center', size=10)
plt.show()Visualize detrended data
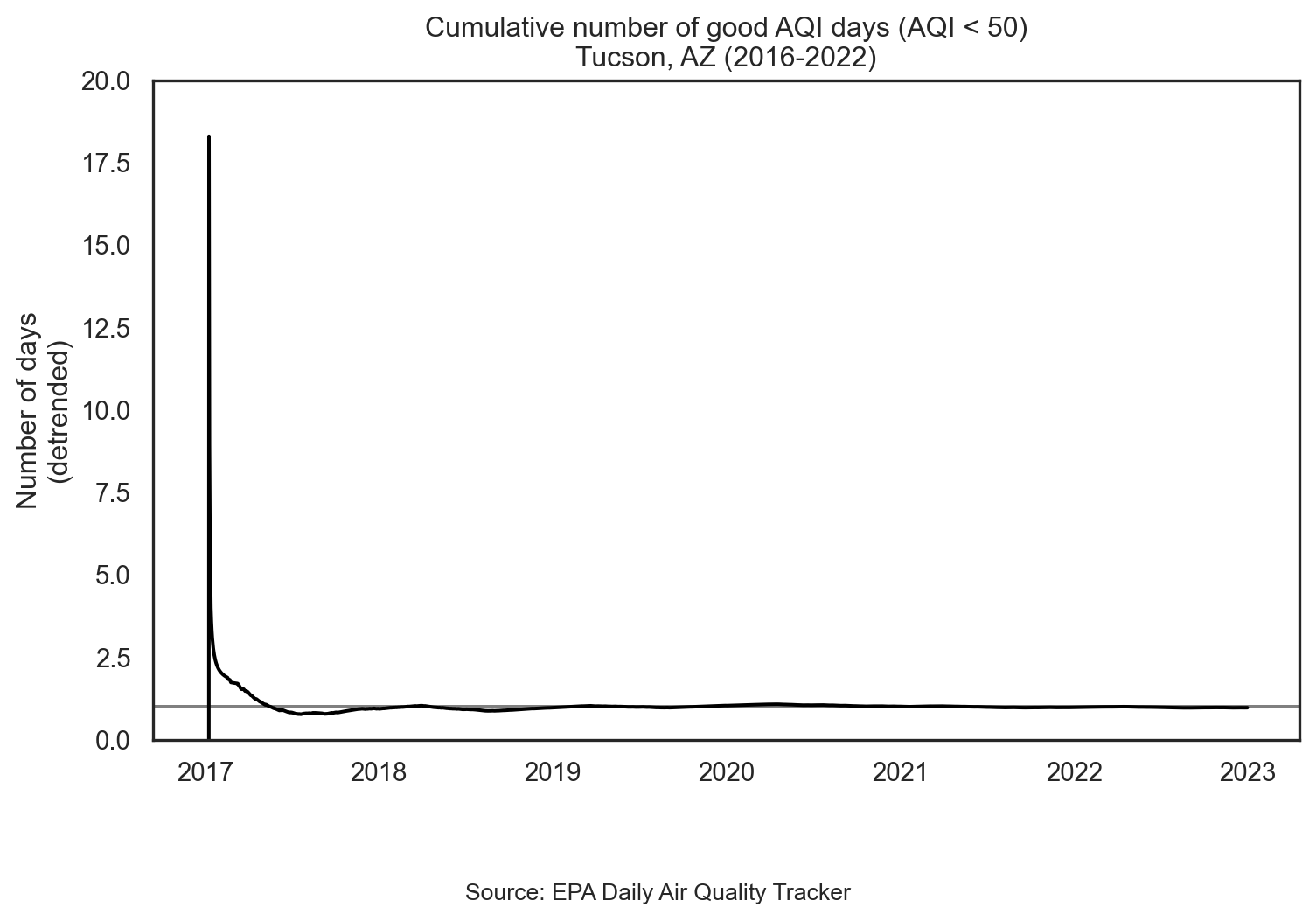
plt.axhline(y=1, color='gray')
sns.lineplot(data=tuc, x='date', y='ratio', color='black')
plt.gca().xaxis.set_major_formatter(DateFormatter("%Y"))
plt.ylim([0, 20])
plt.xlabel(None)
plt.ylabel("Number of days\n(detrended)")
plt.title("Cumulative number of good AQI days (AQI < 50)\nTucson, AZ (2016-2022)")
plt.figtext(0.5, -0.1, 'Source: EPA Daily Air Quality Tracker', ha='center', size=10)
plt.show()Plot trend since 2016
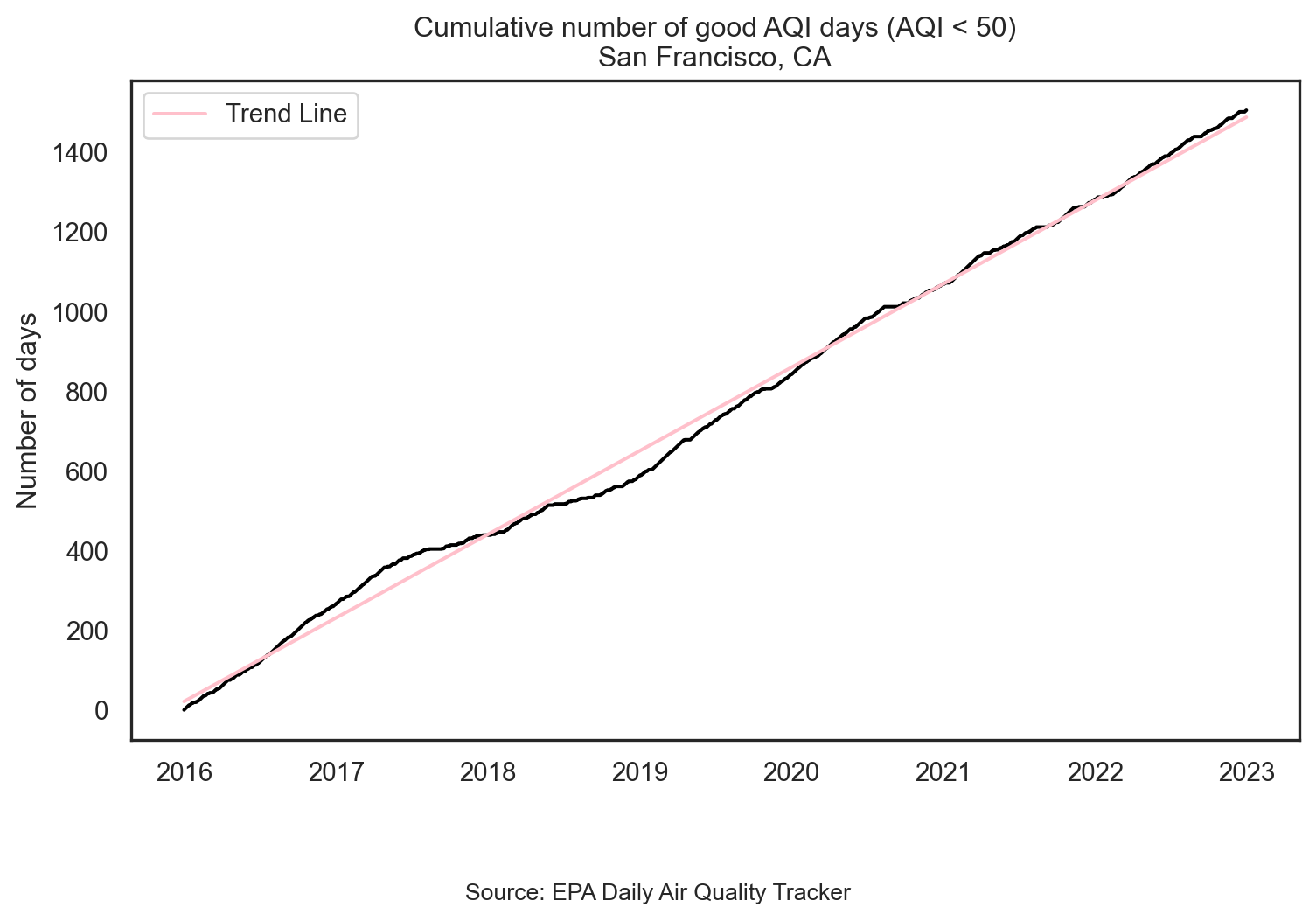
sns.lineplot(data=sf, x='date', y='cumsum_good_aqi', color = 'black')
sns.lineplot(data=sf, x='date', y='fitted', color='pink', label='Trend Line')
plt.gca().xaxis.set_major_formatter(DateFormatter("%Y"))
plt.xlabel(None)
plt.ylabel("Number of days")
plt.title("Cumulative number of good AQI days (AQI < 50)\nSan Francisco, CA")
plt.figtext(0.5, -0.1, 'Source: EPA Daily Air Quality Tracker', ha='center', size=10)
plt.show()Visualize detrended data
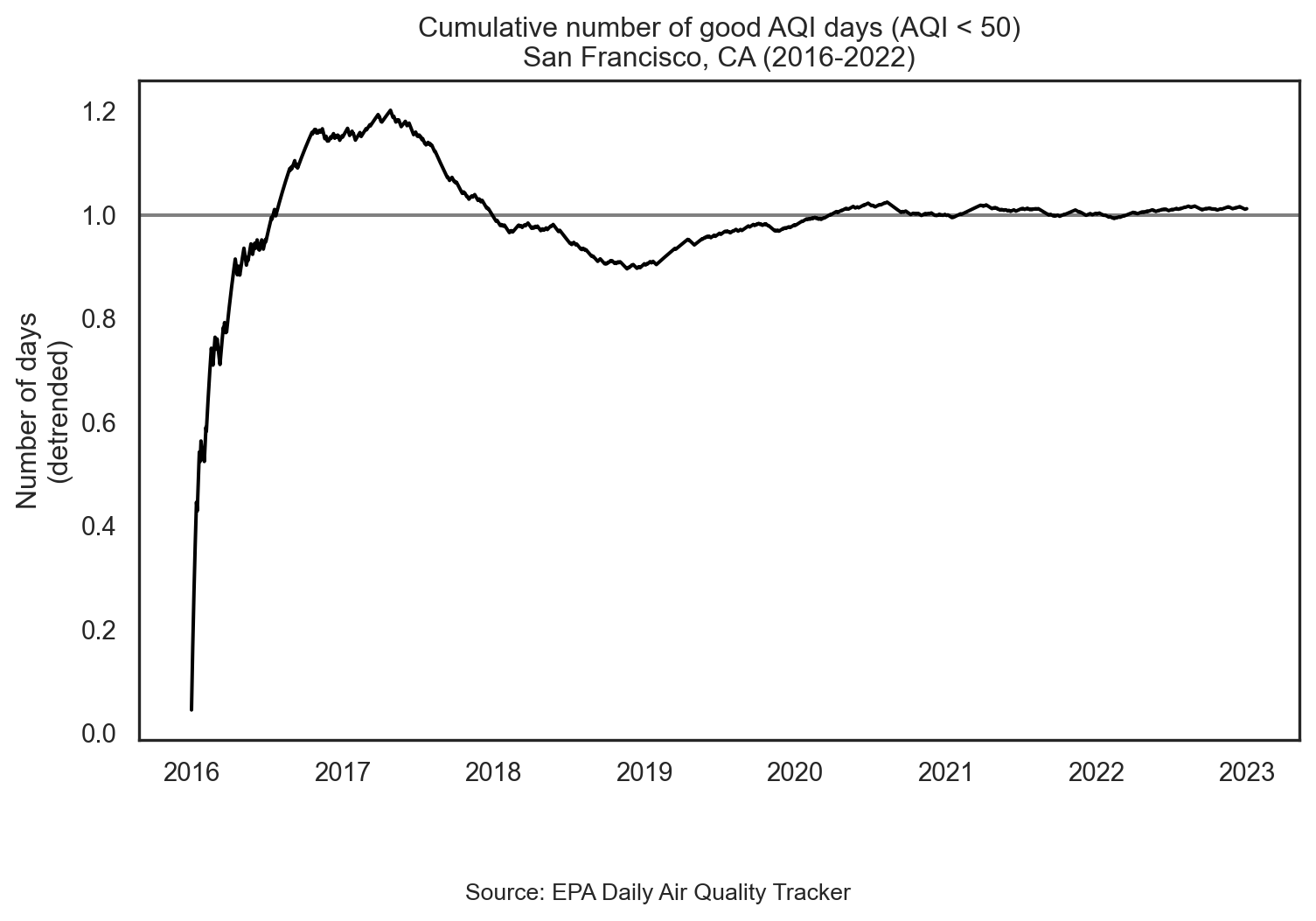
plt.axhline(y=1, color='gray')
sns.lineplot(data=sf, x='date', y='ratio', color='black')
plt.gca().xaxis.set_major_formatter(DateFormatter("%Y"))
plt.xlabel(None)
plt.ylabel("Number of days\n(detrended)")
plt.title("Cumulative number of good AQI days (AQI < 50)\nSan Francisco, CA (2016-2022)")
plt.figtext(0.5, -0.1, 'Source: EPA Daily Air Quality Tracker', ha='center', size=10)
plt.show()Plot AQI over years
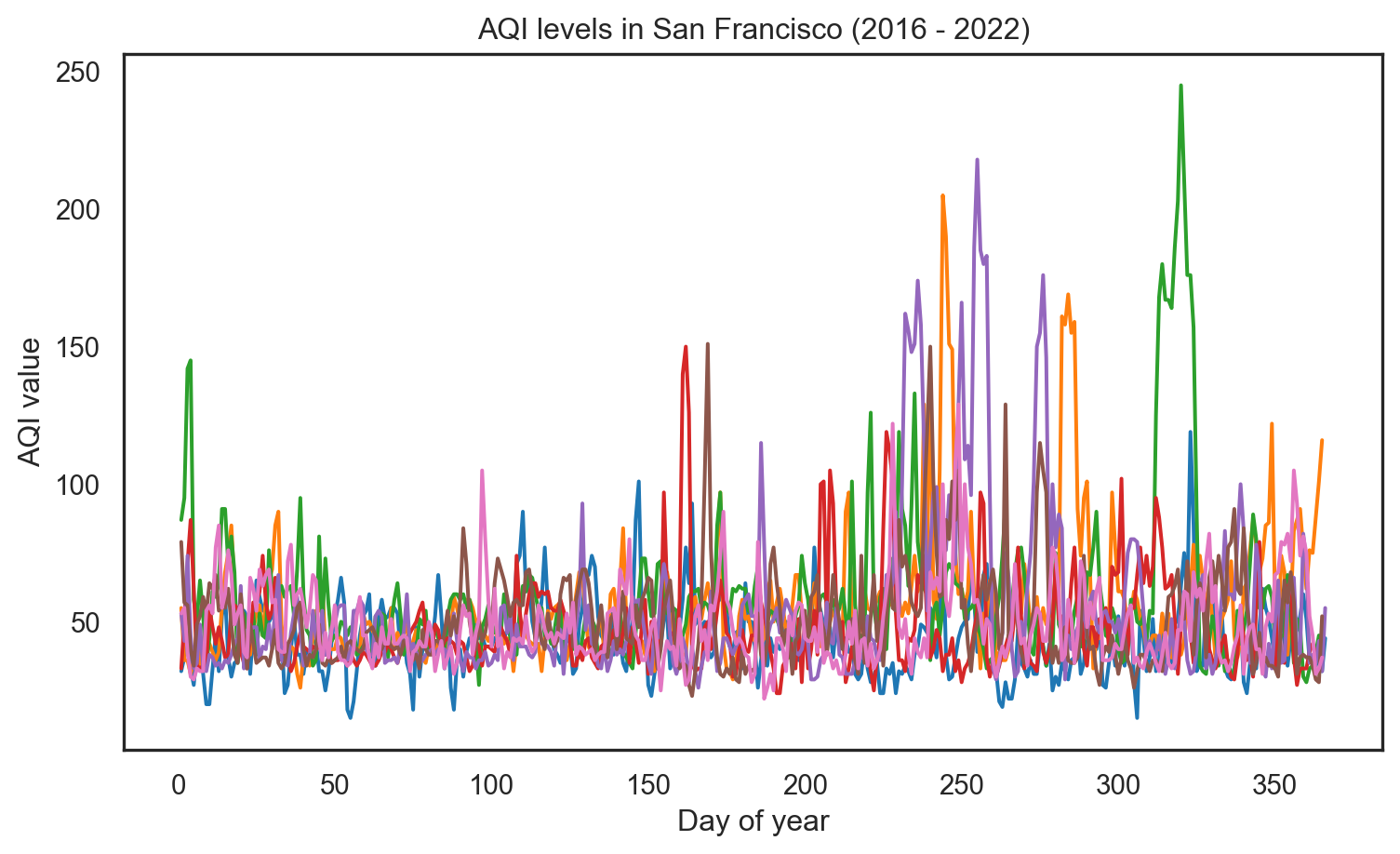
Highlight specific year (2016)
Code
# Highlight the year 2016
sns.lineplot(data=sf, x='day_of_year', y='aqi_value', color='gray')
sns.lineplot(data=sf[sf['year'] == 2016], x='day_of_year', y='aqi_value', color='red')
plt.xlabel('Day of year')
plt.ylabel('AQI value')
plt.title('AQI levels in SF in 2016\nVersus all years 2016 - 2022')
plt.show()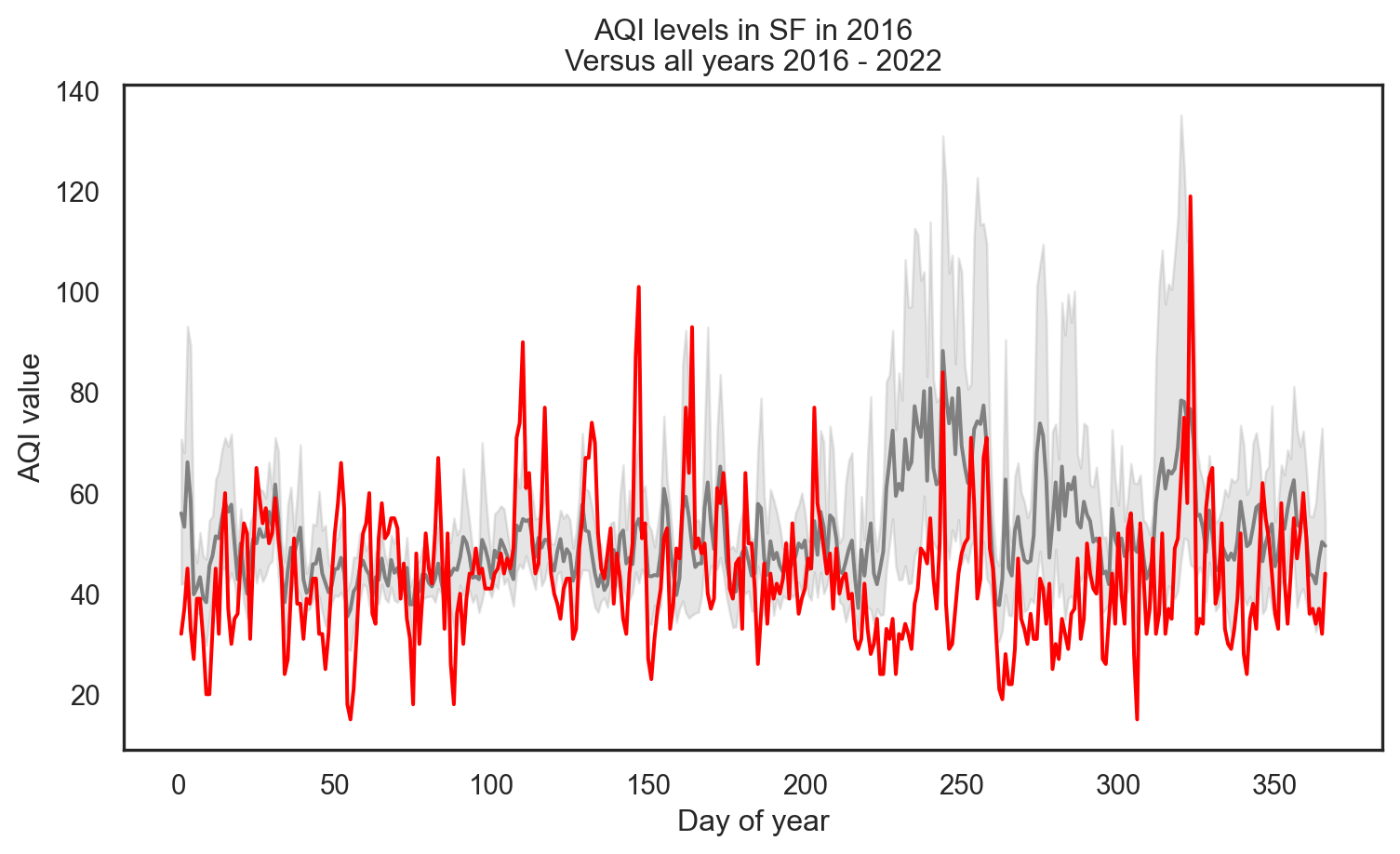
Highlight specific year (2017)
Code
# Highlight the year 2017
sns.lineplot(data=sf, x='day_of_year', y='aqi_value', color='gray')
sns.lineplot(data=sf[sf['year'] == 2017], x='day_of_year', y='aqi_value', color='red')
plt.xlabel('Day of year')
plt.ylabel('AQI value')
plt.title('AQI levels in SF in 2017\nVersus all years 2016 - 2022')
plt.show()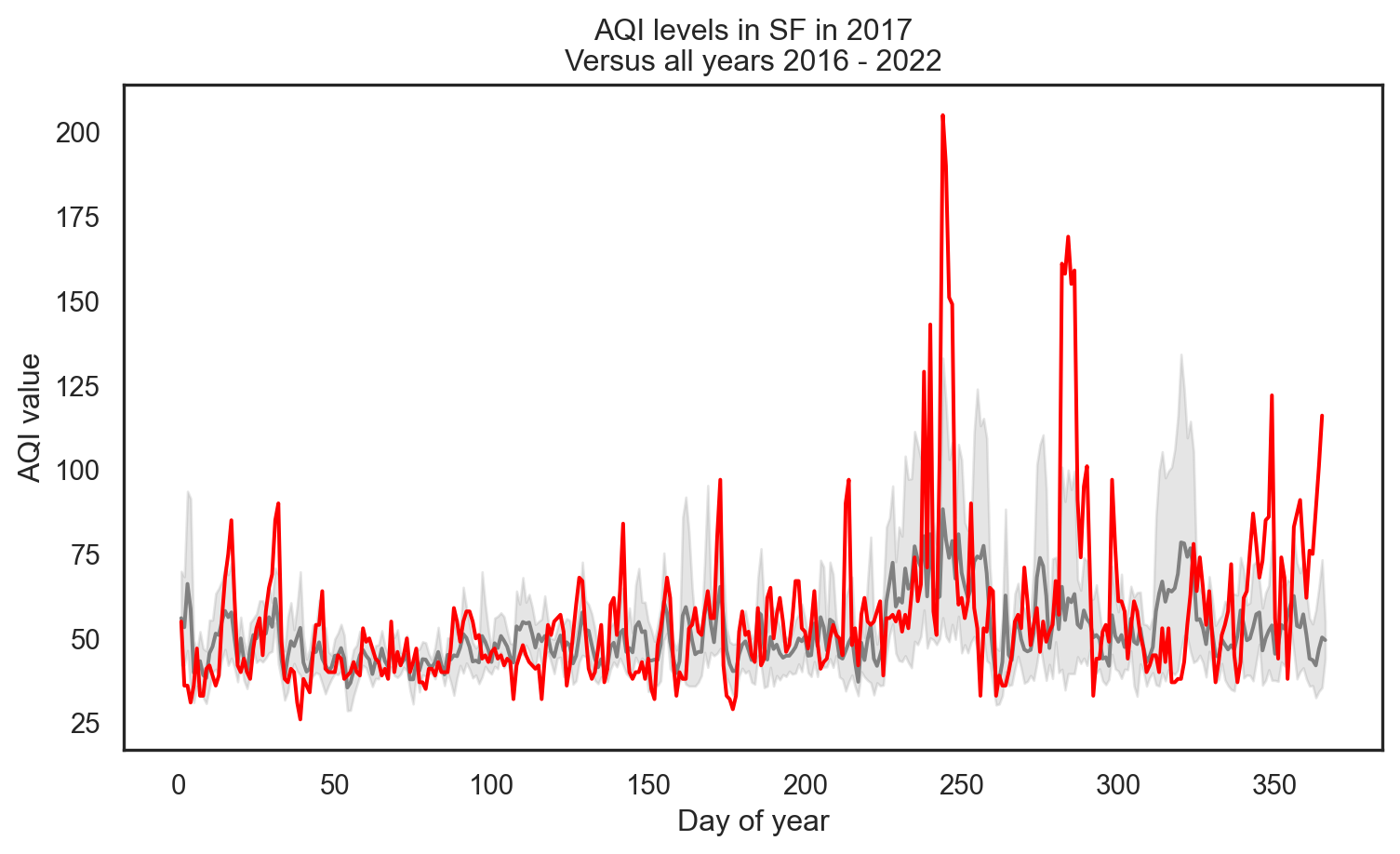
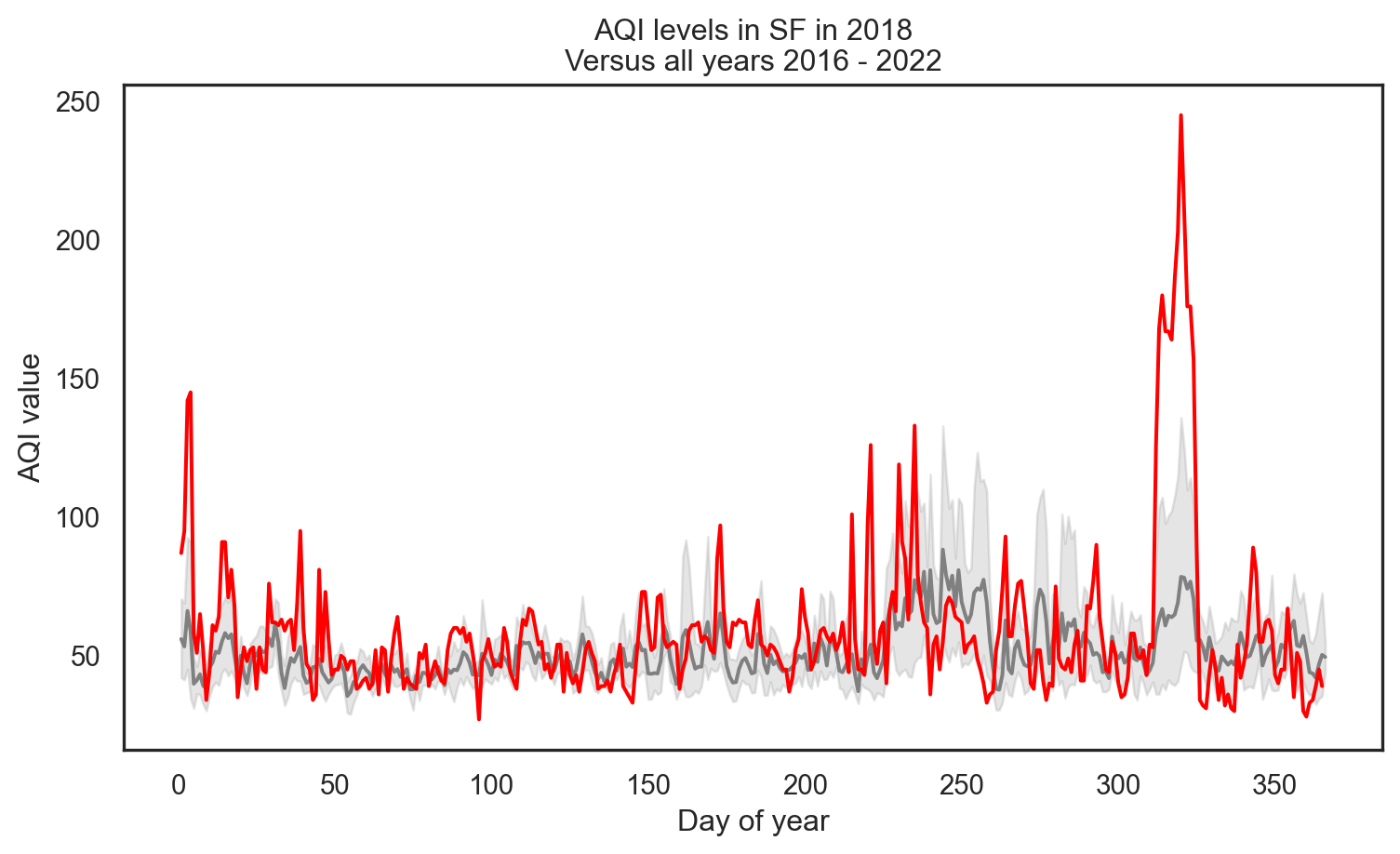
Highlight specific year (2018)
Code
# Highlight the year 2018
sns.lineplot(data=sf, x='day_of_year', y='aqi_value', color='gray')
sns.lineplot(data=sf[sf['year'] == 2018], x='day_of_year', y='aqi_value', color='red')
plt.xlabel('Day of year')
plt.ylabel('AQI value')
plt.title('AQI levels in SF in 2018\nVersus all years 2016 - 2022')
plt.show()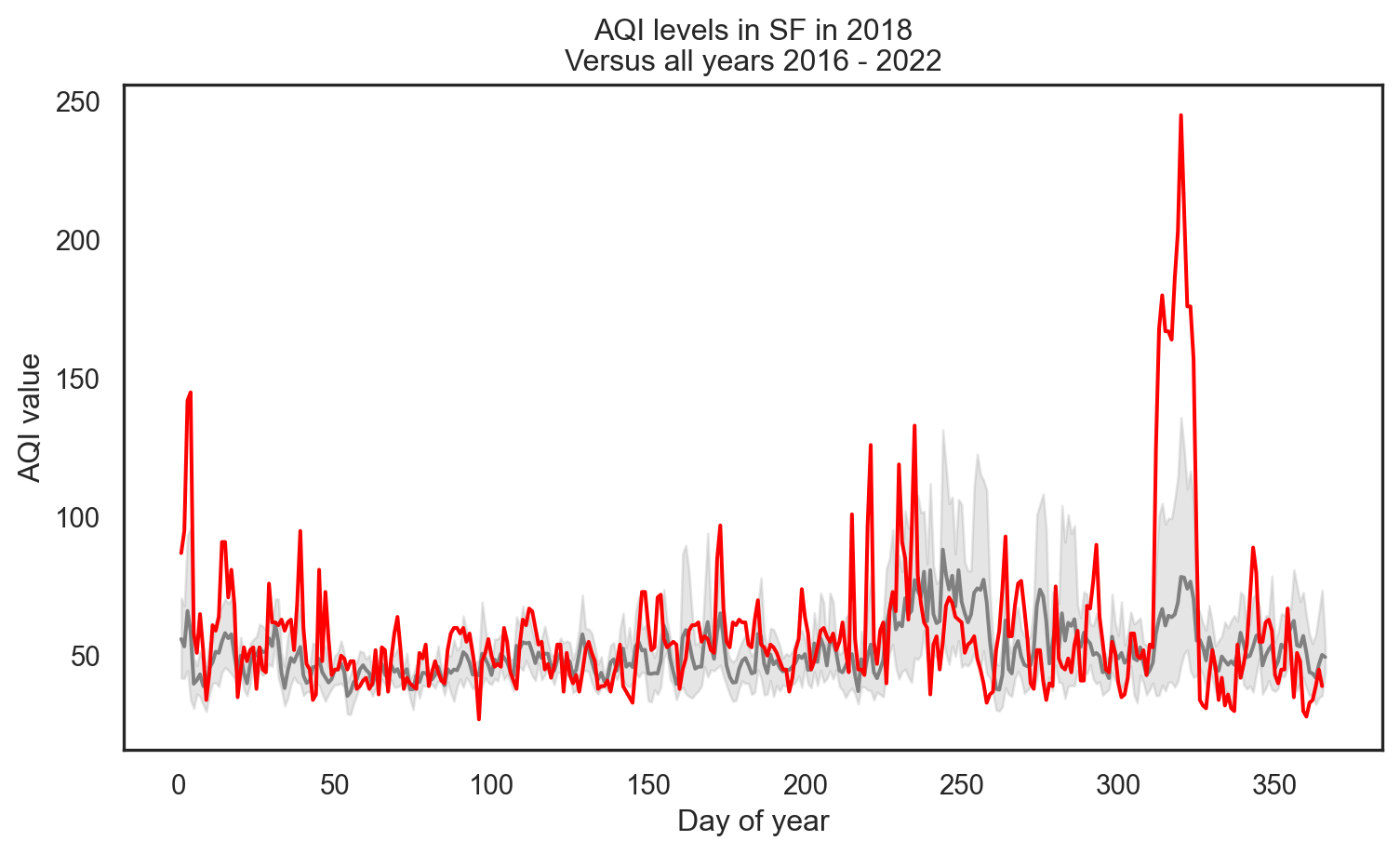
Highlight any year
Code
# Function to highlight a specific year
def highlight_year(year_to_highlight):
sns.lineplot(data=sf, x='day_of_year', y='aqi_value', color='gray')
sns.lineplot(data=sf[sf['year'] == year_to_highlight], x='day_of_year', y='aqi_value', color='red')
plt.xlabel('Day of year')
plt.ylabel('AQI value')
plt.title(f'AQI levels in SF in {year_to_highlight}\nVersus all years 2016 - 2022')
plt.show()
# Highlight any year
highlight_year(2018)